Namu | 나무 개발자 블로그입니다
[방통대] 자료구조! by namu

목차
참조
- 정광식, 방송통신대학교 자료구조 강의, 2021
1. 자료구조란 무엇인가?
2학년 기초과목인 자료구조입니다!
1.1 자료와 정보 사이의 관계
DATA 로 표현되는 자료를 가공해 정보(Information)를 만듭니다.
여기서 가공은 컴퓨터가 수행하며 이 과정을 처리, 즉 프로세스라고 합니다.
I = P(D)
가공된 정보는 유의미해서 이에 맞는 다음 행위를 결정하는데 사용됩니다. 예를 들어 입출금 내역 정보를 통해 돈통에 잔돈이 얼마나 남아 있는지, 부족하진 않는지 빠르게 판단할 수 있습니다.
컴퓨터과학 초창기에는 처리된 정보에 많은 초점이 맞춰져 있었다면, 현재는 빅데이터의 발전으로 대용량의 자료Data를 얼마나 효과적으로 다루는지도 중요하게 되었습니다.
자료의 정의
현실 세계에서 관찰이나 측정을 통해서 수집된 값이나 사실
좋은 자료구조는 정리가 잘 되어 있다??
컴퓨터과학 관점에서는 컴퓨터의 처리 효율성이 최대가 될 수 있도록 목록별, 주제별, 구조적으로 잘 정리된 자료구조를 좋은 자료구조라 합니다.
그리고 정보의 정의는 다음과 같습니다.
정보의 정의
어떤 상황에 대해서 적절한 의사결정을 할 수 있게 하는 지식으로써 자료의 유효한 해설이나 자료 상호 간의 관계를 표현하는 내용
1.2 추상화의 개념
수도권 지하철 노선도를 생각해 봅시다.
역과 노선이 굉장히 유기적으로 그려져 있지만, 그렇다고 이것이 실제 물리적 노선과 일치하는 것은 아닙니다. 모든 자료 중 정보전달에 꼭 필요한 부분만 추출되어 사람이 이해하기 쉽게 추상화되어 있기 때문입니다.
만약 우리가 지하철 경로를 설명한다면 이와 같이 필요한 부분만 뽑아내어 추상화된 개념으로 설명하게 될 것입니다.
추상화
공통적인 개념을 이용하여 같은 종류의 다양한 객체를 정의하는 것
“버스 타고 수원까지 가자!” 라는 추상화된 말에는 버스의 종류, 요금, 노선, 그리고 출발지와 목적지의 구체적인 정보가 내포되어 있습니다.
그렇다면 컴퓨터과학에서 자료의 추상화는 어떻게 설명할까요?
자료의 추상화
다양한 객체를 컴퓨터에서 표현하고 활용하기 위해 필요한 자료의 구조에 대해서 공통의 특징만을 뽑아 정의한 것
컴퓨터과학에서는 자료의 추상화를 통해 컴퓨터 내부의 이진수의 표현 방법, 저장 위치 등 구체적인 정보는 굳이 표현하지 않고 단순하게 개발자의 머릿속에 그림을 그리는 것처럼 개념화합니다.
1.3 자료구조의 개념
자료를 추상화, 구조화하는 것을 자료구조라 합니다.
자료구조
추상화를 통해 알고리즘에서 사용할 자료의 논리적 관계를 구조화한 것
1.4 자료구조와 알고리즘의 관계
자료구조가 컴퓨터가 처리할 자료를 추상화하는 과정이라면, 알고리즘은 컴퓨터가 수행할 명령을 추상화하는 과정입니다.
입력된 자료를 자료구조를 통해 추상화/구조화하고, 추상화된 알고리즘을 수행해 출력할 결과를 만들어냅니다. 여기서 프로그램이 하는 일은 알고리즘을 구현해 실제 동작하게 하는 것입니다.
알고리즘이란?
- 사람이 컴퓨터에게 일을 시키는 명령어의 연속된 덩어리
- 명령어의 유한 집합이 사람의 머릿속에 추상화되어 존재하는 것
- 사람이 컴퓨터에게 일을 시키기 위한 명령 / 명령을 전달하기 위한 방법(언어/글)
- 알고리즘의 조건
- 출력, 유효성, 입력, 명확성, 유한성
1.5 알고리즘 성능의 분석과 측정
알고리즘의 성능 분석은 실행하는 데 필요한 시간과 공간을 추정하여 수행합니다.(-> 예측의 영역)
알고리즘의 성능 측정은 컴퓨터가 실제로 프로그램을 실행하는데 걸리는 시간을 측정합니다.(-> 측정의 영역)
- 실행 시간의 측정
- 실제 시계로 재기
- 실제로 실행될 수 있는 프로그램(실행 파일)이 필요
- 시스템 시계를 이용
2. 배열
배열은 자료의 추상화된 의미와 구체화된 의미가 유사한 자료구조입니다.
자료의 순서성이 매우 중요하며, 이 인덱스는 실제 메모리에 물리적으로 저장되는 주소의 순서와 유사합니다.
2.1 배열의 정의
배열의 정의는 다음과 같습니다.
배열
[사전적 의미] 일정한 차례나 간격에 따라 벌여 놓음
[정의 1] 차례(순서)와 관련된 기본적인 자료구조
[정의 2] 인덱스와 원소값(<index, value>)의 쌍으로 구성된 집합
인덱스 자체가 순서성을 포함하고 있습니다. 따라서 인덱스로 특정 위치의 값에 접근 가능합니다.
또한 한 배열의 모든 원소들은 같은 자료형과 같은 크기의 기억공간을 갖습니다.
인덱스와 메모리 주소의 순서가 유사하다는 말의 의미는, 인덱스 숫자(개념적)와 메모리 주소값(주소)은 서로 다르지만 순서적으로 동일하다는 것입니다.
따라서 개발자가 인덱스로 배열에 접근하면 운영체제가 이에 해당하는 물리 주소로 연결해줍니다.
2.2 배열의 추상 자료형
교수님이 설명하시는 추상 자료형이란 call by reference 되는 따로 정의된 객체 혹은 연산을 의미하고,
자료형은 int, float 등과 같이 직접 메모리에 할당되는 원시Primitive 타입(call by value)을 의미합니다.
추상 자료형
객체 및 관련된 연산의 정의
자료형
메모리 저장 할당을 위한 선언
그럼 이제 배열의 추상 자료형을 살펴보겠습니다.
앞서 설명했듯, 배열은 추상 자료형이므로 객체 타입입니다. 이러한 배열 객체와 연산 가이드라인을 살펴보면,
- ADT Array 객체
- Index: 순서를 나타내는 우너소의 유한집합
- Element: 타입이 같은 원소의 집합
따라서, 배열 구현 시 A[1] 은 배열 A 의 1번 인덱스의 값을 지징하는 것으로 개념화할 수 있습니다.
- 연산
- a: 0개 이상의 원소를 갖는 배열
- item: 배열에 저장되는 원소
- n: 배열의 최대 크기를 정의하는 정수값
Array create(n) ::= 배열의 크기가 n인 빈 배열을 생성하고 배열을 반환Element retrieve(a, i) ::=if (i in Index) then {배열의 i번째에 해당하는 원소값 'e' 를 반환;} else {에러 메시지 반환;}
Array store(a, i, e) ::=if (i in Index) then {배열 a의 i번째 위치에 원소값 'e'를 저장하고 배열 a를 반환;} else {인덱스 i가 배열 a의 크기를 벗어나면 에러 메시지 반환;}
2.3 배열의 연산의 구현
위와 같은 배열 객체와 연산의 개념을 c 를 사용하여 다음과 같이 구현할 수 있습니다.
[연산 void create()]
void create(int *a, int n) { // n = 5
int i;
for (i = 0; i < n; i++) {
a[i] = 0;
}
}
- 첫 번째 인자
int *a는 생성된 배열 a 의 주소값 - 주어진 숫자
int n이 5 라면 총 다섯칸이며, 배열 a 의 인덱스 4 까지 0 ~ 4 의 숫자가 각각 요소로 들어감
배열 a 의 각 요소는 a[0], a[1], ..., a[4] 와 같은 방식으로 접근할 수 있습니다.
[연산 int retrieve()]
#define array_size 5
int retrieve(int *a, int i) { // i = 2
if (i >= 0 && i < array_size) {
return a[i];
} else {
printf("Error\n");
return -1;
}
}
이러한 구현 로직에 따라 시스템 개발자는 컴파일러를 만듭니다. 잘 만들어진 컴파일러라면 range 를 벗어나는 인덱스 접근 시 에러를 발생시키게 됩니다.
2.4 1차원 배열 및 배열의 확장
1차원 배열은 한 줄짜리 배열을 의미하며, 각 요소는 하나의 인덱스로 구분됩니다.
운영체제가 1차원 배열의 인덱스를 따라 실제 물리적 주소를 찾아가는 방식은 다음과 같습니다.
- 배열 A[] 의 첫 번째 원소 A[0] 의 물리 주소가 a 이고, i 인덱스에 해당하는 요소에 저장된 값을 찾을 때,
- A[i] 의 물리 주소 계산식은
a + i * k입니다.(k 는 메모리 할당 단위, 즉 요소별 저장공간의 크기) - 이는 추상적 순서성과 물리적 순서가 일치하기 때문에 가능합니다.
- A[i] 의 물리 주소 계산식은
만약 배열 A 의 첫 번째 인덱스의 물리 주소가 십진수 100 이고 메모리 할당 단위가 2면, 5번 인덱스의 값을 찾기 위해서는,
a + i * k = 100 + 5 * 2 = 110
110 의 물리 주소로 찾아가게 됩니다!
참고로 0번 인덱스는 100 + 0 이 되어 첫 주소인 100 을 나타냄을 기억하세요.
다음으로 배열의 확장으로는 행렬을 꼽을 수 있는데, 행렬의 배열 표현을 위해서는 2차원 배열이 적합합니다.
[3x4 2차원 배열의 예]
5 2 6 2
7 2 0 0
0 1 1 9
[3x4 2차원 배열의 인덱스 표현]
A[0][0] A[0][1] A[0][2] A[0][3]
A[1][0] A[1][1] A[1][2] A[1][3]
A[2][0] A[2][1] A[2][2] A[2][3]
위의 방식을 행 우선 배열이라고 하는데, 한 행이 하나의 일차원 배열로 이루어졌기 때문입니다.
열 우선 배열은 반대로 생각하면 됩니다. 행 우선 배열이 주로 사용됩니다.
행 우선 배열이 물리적으로도 좋은 이유
2x2 의 경우 행 우선 배열이라면 [0, 0], [0, 1], [1, 0], [1, 1] 의 순서로 저장됩니다.
이러한 2차원 인덱스 방식은 곧 2진수 물리 주소의 순서를 그대로 따르기 때문에(00, 01, 10, 11) 불필요한 이동 없이 순서대로 최적 접근이 가능합니다.
반대로 열 우선 배열은 이 순서가 바뀌어 순서대로 물리적인 접근이 불가합니다. 이는 데이터 양이 많아지고 저장장치의 성능이 낮을수록 현저한 속도 저하를 불러오게 됩니다.
2.5 희소행렬의 개념
2차원 배열을 활용한 행렬의 응용입니다.
희소행렬의 개념은 사이즈가 큰 2차원 배열에서 0 값이 다수 존재하는 경우 메모리를 더 효율적으로 다루기 위한 방법입니다.
따라서 반복적으로 저장되는 0 값은 굳이 메모리에 저장하지 않고, 0 이 아닌 값만을 따로 모아서 저장하는 방식으로 추상화합니다.
8행 9열의 2차원 배열을 희소행렬로 추상화한 결과는 다음과 같습니다.
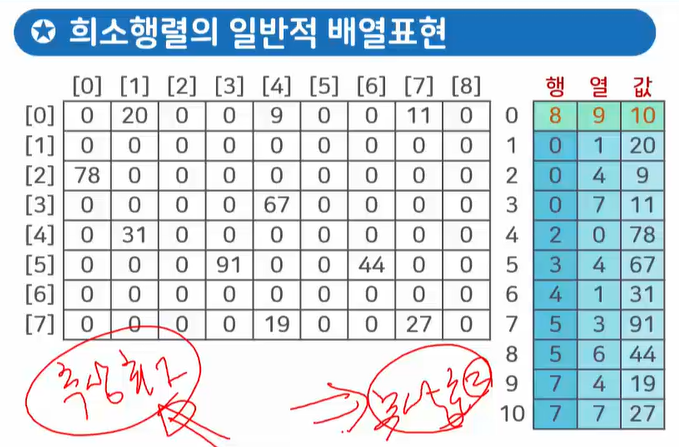
위와 같이 한번 더 추상화된 희소행렬에서 첫 번째 행은 2차원 배열의 행, 열, 값(0이 아닌 값의 개수)을 나타냅니다.
그 다음 행부터는 가로 인덱스, 세로 인덱스, 실제 값을 표현합니다.
이로써 불필요한 0을 제외하고 꼭 필요한 정보만 추상화해 메모리 공간을 더 효율적으로 사용하게 되었습니다!
3. 스택
스택은 LIFO 으로, 주로 값을 역순으로 추적하거나 왔던 길을 되돌아가는 경우 많이 사용됩니다. 나아가 역순을 활용하면 순환 호출(재귀적)이 가능합니다.
스택에서 주의할 점은 데이터가 사전에 정의된 스택의 크기가 넘어가는지 여부입니다.
넘어가면
스택오버플로
가 발생하게 됩니다.
스택은 배열과 관련이 깊습니다.
3.1 스택의 개념과 추상 자료형
책을 쌓아놓은 그림을 상상해 봅시다.
스택의 추상 자료형은 삽입과 삭제의 위치가 동일하며, 중간값을 삽입/변경/삭제하지 못하는 형태입니다. 오직 한 위치에서만 삽입과 삭제가 가능합니다.
스택
- 객체와 그 객체가 저장되는 순서를 기억하는 방법에 관한 추상 자료형
- 0개 이상의 원소를 갖는 유한 순서 리스트
- push(add)와 pop(delete) 연산이 한 곳에서 발생되는 자료구조
3.2 스택의 응용과 구현
스택은 대표적으로 다음의 상황에서 활용됩니다.
- 변수에 대한 메모리의 할당과 수집을 위한 시스템 스택
- 서브루틴 호출 관리를 위한 스택
- 연산자들 간의 우선순위에 의해 계산 순서가 결정되는 수식 계산
- 인터럽트의 처리와, 이후 리턴할 명령 수행 지점을 저장하기 위한 스택
- 컴파일러, 순환 호출 관리
특히 시스템에서는 여러 함수가 중첩되어 호출된 경우, 스택에 쌓인 각각의 호출 순서에 따라서 실행할 우선순위와 컨텍스트를 결정합니다. (main 함수가 가장 밑바닥이며, 그 위의 중첩된 함수들이 모두 끝나야 main 도 종료)
다음은 스택의 연산입니다.
- 스택의 연산
- 스택의 삭제 연산을 살펴보면,
- ‘top–‘에서 사용된 ‘–’ 연산자의 위치에 따라 연산의 적용순서가 달라질 수 있음
int a; a = 5; b = a--; // a = 4, b = 5int a; a = 5; b = --a; // a = 4, b = 4
위 삭제연산 예제에서, 전자의 후위 ‘–’ 연산은 a 를 b 에 대입한 이후에 수행됩니다. 반대로 전위 ‘–’ 연산은 먼저 수행된 이후에 대입됩니다.
스택의 삽입 연산 ‘++’ 도 이것과 같은 논리이므로, 올바른 스택의 input/output 수행을 위한 스택의 재귀 호출시에는,
삭제 연산의 top 은 후위로, 삽입 연산은 전위로 연산되어야 합니다.
3.3 사칙 연산식의 전위/후위/중위 표현
수식에서 표현되는 연산자들의 계산 순서에 따라 그 결과는 매우 달라집니다.
A+B*C+D 의 계산
일반적 우선순위(중위): ((A+(BC))+D) 전위 표기법: +(+A(BC))D » ++ABCD 후위 표기법: (A(BC)+)D+ » ABC*+D+
컴퓨터에서는 후위 표기법으로 우선순위를 표기하며 실제 계산은 스택을 활용합니다.
ABC*+D+ 표현식의 경우는 후위 표기법이라는 사실을 알면 괄호가 없어도 스택에 따라 계산이 가능합니다.
스택 연산 순서는 연산자가 나오면 연산의 대상이 되는 두 수가 나올 시 연산하고, 그 전에 새 연산자가 또 나오면 새 연산자에 해당하는 두 수를 먼저 연산하는 우선순위에 따라 이루어집니다.
혹은 반대로 수를 먼저 꺼내고 연산자가 나오면 직전 두 수에 대해 연산하는 우선순위로 진행할 수도 있습니다.
4. 큐
큐는 입출력 순서를 중심으로 자료 간 관계가 성립된다는 면에서 스택과 유사하지만, FIFO(선입선출) 라는 면에서 차이가 있습니다.
큐의 예시로는 앞에서부터 줄을 서는것을 생각하면 좋습니다. 따라서, 자원의 할당을 받으려는 작업들 간의 순서를 관리하기 위해 사용됩니다.
큐 또한 사전에 정의된 크기를 고려해야 하며, 원소 삭제 시에도 삭제할 원소가 남아있는지도 확인해야 합니다.
나아가 큐를 활용한 CPU 할당 방법(Round Robin)을 살펴보고 메모리 효율성을 높힐 원형 큐에 대해 이해해 보겠습니다.
4.1 큐의 개념 및 추상 자료형
큐는 줄을 서는 것, 정수기의 종이컵을 순서대로 뽑는 것 등으로 상상해볼 수 있습니다. 이들은 공통적으로 먼저 진입한 요소가 먼저 처리되는 특징이 있습니다.
LIFO 인 스택과 비교해서 생각해 봅시다. 쌓여있는 책에서 제거할 수 있는 것은 가장 마지막에 올려진 책입니다.
컴퓨터 OS 에서 큐는 작업 스케줄링을 하거나 CPU 작업 할당을 할 때 주로 활용됩니다.
큐의 의미와 연산
한 쪽에서는 삽입 연산만 발생 하능하고,
다른 한 쪽에서는 삭제 연산만 발생 가능한 양쪽이 모두 터진 관!
- 한 쪽에서 삽입(rear)
- 서비스를 받기 위한 기다림
Queue Add_q (queue, item) { if ( IsFull_q(queue) ) { 'queueFull' 출력; } else { 큐의 rear 에 item 삽입 후 큐 반환; } }- 반대편에서 삭제(front)
- 서비스를 받는 중
Element Delete_q (queue) { if ( IsEmpty_q(queue) ) { 'queueEmpty' 출력; } else { 큐의 front 원소를 제거 후 반환; } }- 큐의 만원 검사(IsFull_q)
- 큐가 가득 찼는지 확인
Boolean IsFull_q (queue, maxQueueSize) { if ( (queue 의 element 개수) == maxQueueSize ) { 'TRUE' 값 반환; } else { 'FALSE' 값 반환; } }- 빈 큐 검사(IsEmpty_q)
- 큐가 비어 있는지 확인
Boolean IsEmpty_q (queue) { if ( rear === front ) { 'TRUE' 값 반환; } else { 'FALSE' 값 반환; } }
rear 와 front 를 굳이 구분하지 않아도 됩니다. 한 쪽에서 삽입이 이루어지면 반대편에서는 삭제가 이루어지도록 하면 됩니다.
4.2 큐의 응용
큐 자료구조는 CPU 작업 할당시 주로 사용됩니다.
- FCFS(First-Come First-Service, equals to FIFO)
- 스케줄링 기법은 작업(프로그램)이 준비 큐(Ready queue)에 도착한 순서대로 CPU 를 할당받도록 해 주는 기법입니다.
- 준비 큐에 A, B, C 순서대로 작업 요청이 들어오면 순서대로 처리됩니다.
위와 같은 큐 방식으로 파일 다운로드 프로세스를 수행하면 다운로드 자체는 네트워크 아답터가 수행하기 때문에 CPU 는 점유된 상태로 머무는 문제가 발생합니다.
- RR(Round-Robin)
- RR 은 기본적인 큐 작업 스케줄링에서 각 작업의 수행시간에 제한을 두는 것입니다.
- 따라서 제한시간 내에 완료되지 않은 작업은 큐의 rear 에 재할당 됩니다.(완료된 작업은 제거)
라운드 로빈은 CPU 작업 스케줄링뿐 아니라 네트워크 분산처리에서도 빈번히 활용됩니다.
4.3 배열을 이용한 큐의 구현
변수 rear 의 초기값은 큐의 공백 상태를 나타내는 ‘-1’ 로 시작합니다.
#define QUEUE_SIZE 5
typedef int element;
element queue[QUEUE_SIZE];
int front = -1;
int rear = -1;
void Add_q(int *rear, element item) {
if (*rear == QUEUE_SIZE - 1) {
printf("Queue is full!");
return;
}
queue[++(*rear)] = item;
return ;
}
element Delete_q(int *front, int rear) {
if (*front == rear) {
printf("Queue is empty\n");
return;
}
return (queue[++(*front)]);
}
4.4 원형 큐
일반적인 큐는 rear, front 포인터가 증가하며 삽입/삭제되기 때문에 나중에는 비어 있는 공간이 발생하게 됩니다.
할당된 큐의 메모리 낭비를 방지하기 위하여 원형 큐를 사용합니다. 원형 큐는 파이프의 입구와 출구 부분을 연결시킨 형태입니다.
삽입 시 rear 에 데이터가 들어가는 것은 동일합니다. 하지만 일반 큐에서 rear 의 위치가 배열의 마지막 인덱스라면 full 로 간주하여 더 이상 삽입이 안 되었던 반면, 원형 큐에서는 첫 번째 인덱스와 마지막 인덱스가 연결되었으므로 rear 의 다음 칸이 비어있는지 확인만 가능하다면 그곳에 새 데이터를 삽입할 수 있습니다.
따라서 원형 큐에서는 다음 칸이 빈 공간인지만 확인하면 됩니다. 실제 구현에서는 rear 의 다음 공간 인덱스를 front 가 가리키고 있다면 원형 큐가 만원입니다!
원형 큐의 빈 공간 확인 시 유의점
기본적으로 큐의 추상화 정의에 따라 rear == front 는 빈 큐를 의미합니다.
하지만 원형 큐의 실제 구현에서 rear == front 는 만원을 의미하기도 합니다.따라서 QUEUE_SIZE 와 실제 데이터가 들어있는 공간 개수의 count 가 같은지도 체크하는 로직을 함께 구현해 구분하도록 합니다!
(혹은 구현상으로 초기에는 rear == front 가 성립되지 않은 채 시작되도록 할 수도 있음)
5. 연결 리스트
5.1 리스트의 개념
- 리스트는 일정한 순서의 나열
- 어떤 정의에 의해서 결정된 ‘논리적인 순서’의 나열
배열과 달리 연결 리스트는 물리적인 순서가 보장되지는 않습니다. 하지만 개발자는 원소들을 논리적인 순서로 확인할 수 있습니다.
논리적 순서만 보장되는 연결 리스트를 구현하려면 포인터를 활용하거나 배열을 활용할 수 있습니다.
5.2 배열을 이용한 리스트의 구현
배열로 리스트를 구현할 수 있습니다. 이 때는 배열의 인덱스 순서와 물리적 순서가 동일합니다.
하지만 만약 중간에 새 데이터가 추가되거나 삭제되면 그 이후의 모든 원소들의 이동이 수반됩니다. 또한 배열의 크기를 늘리는 경우(확장)에도 비용이 추가 소요되며, 너무 큰 사이즈로 할당해 두면 자원의 낭비가 있습니다.
배열을 이용한 리스트의 구현은 단순하고 쉽지만, 삽입과 삭제, 메모리 관리에 있어서 효율적이지 않습니다.
5.3 포인터를 이용한 리스트의 구현
이 방법에서는 노드를 활용합니다.
노드에는 데이터(data)와 다음 노드를 가리키는 포인터(link)가 존재합니다. 메모리상에서 멀리 떨어진 곳에 다음 노드가 존재해도 그곳의 주소값만 알고 있다면 순서대로 찾아갈 수 있습니다.
따라서 포인터를 이용한 리스트의 구현은 물리적인 순서의 제약이 없으며, 사전에 크기를 제한해두지 않아도 되기 때문에 메모리 관리에 효율적입니다.
[Node 예시]
struct linked_list_node {
int data;
struct linked_list_node* link;
}
5.4 포인터 변수 및 리스트의 삭제와 삽입
[포인터 할당과 반환 예]
int a, *p_a;
float b, *p_b;
p_a = (int*)malloc(sizeof(int));
p_b = (float*)malloc(sizeof(float));
*p_a = 10;
*p_b = 3.14;
printf("a is %d, b is %f\n", *p_a, *p_b);
free(p_a);
free(p_b);
5.5 연결 리스트에서 노드의 삽입과 삭제
- 노드로 구성된 연결 리스트에서 삽입
- 새 노드 생성
- 선행 노드의 link 에 새 노드의 주소(포인터) 삽입
- 새 노드의 link 에 선행 노드가 가지도 있던 다음 노드의 주소(포인터) 삽입
- null 인 경우 null 삽입
- 노드로 구성된 연결 리스트에서 삭제
- 선행 노드의 link 에 삭제할 노드의 link 값(포인터) 삽입
- null 인 경우 null 삽입
- 노드 삭제
6. 연결 리스트의 응용
단순 연결 리스트의 각 노드는 후행 노드에 대한 정보만 가지고 있습니다.
하지만 실질적으로 사용하다 보면 선행 노드의 정보도 필요로 하게 됩니다. 이러한 요구를 충족하는 변형된 연결 리스트가 존재합니다.
6.1 연결 리스트의 변형
변형구조의 대표적인 것이 이중 연결 리스트입니다.
이것은 선행 노드의 link 포인터를 추가로 저장해 역추적이 가능하도록 합니다.
[이중 연결 리스트의 Node 예시]
struct linked_list_node {
int data;
struct linked_list_node* Llink;
struct linked_list_node* Rlink;
}
원형 연결 리스트는 마지막 노드가 시작 노드의 link 포인터를 가져 환형 구조를 형성합니다. 이는 단순 연결 리스트의 마지막 노드의 link 에 null 이 저장됨으로써 선형 구조인 것과 대조됩니다. 원형 연결 리스트는 마지막 노드의 공간을 활용하며 시작 노드로 바로 접근하게 됨으로써 프로그램의 성능이 향상되게 합니다.
6.2 원형 연결 리스트
[원형 연결 리스트의 생성]
typedef struct ListNode { // 원형 연결 리스트의 노드 구조 정의
int data;
struct ListNode* link;
} listNode;
typedef struct { // 원형 연결 리스트의 헤드 노드 구조 정의
listNode* head;
} linkedList_h;
linkedList_h* createLinkedList_h (void) { // 원형 연결 리스트의 헤드 노드 생성
linkedList_h* H;
H = (linkedList_h*)malloc(sizeof(linkedList_h));
H -> head = NULL;
return H;
}
[원형 연결 리스트의 노드 삽입]
void addFirstNode(linkedList_h* H, int x) {
if (H -> head == NULL) { // 현재 리스트가 공백인 경우
H -> head = NewNode;
NewNode -> link = NewNode;
return;
}
tempNode = H -> head;
while (tempNode -> link != H -> head) // 루프 돌며 마지막 노드인지 확인
tempNode = tempNode -> link;
NewNode -> link = tempNode -> link;
tempNode -> link = NewNode;
H -> head = NewNode;
}
6.3 이중 연결 리스트
이중 연결 리스트는 단순 연결 리스트에서 선행 노드를 바로 알 수 없는 문제를 개선한 것입니다.
선행 노드는 Llink, 후행 노드는 Rlink 로 정합니다.
마찬가지로 헤더를 Lhead, Rhead 로 나눌 수 있습니다.
[이중 연결 리스트의 생성]
typedef struct ListNode { // 이중 연결 리스트의 노드 구조 정의
struct ListNode* Llink;
int data;
struct ListNode* Rlink;
} listNode;
typedef struct { // 이중 연결 리스트의 헤드 노드 구조 정의
listNode* Lhead;
listNode* Rhead;
} linkedList_h;
linkedList_h* createLinkedList_h (void) { // 초기화, 원형 연결 리스트의 헤드 노드 생성
linkedList_h* H;
H = (linkedList_h*)malloc(sizeof(linkedList_h));
H -> Lhead = NULL;
H -> Rhead = NULL;
return H;
}
[이중 연결 리스트의 노드 삽입]
void addNode(linkedList_h* H, listNode* prevNode, int x) { // 이중 연결 리스트 노드 삽입 연산, x값은 200 이라고 가정
listNode* NewNode;
NewNode = (listNode*)malloc(sizeof(listNode));
NewNode -> Llink = NULL;
NewNode -> data = x;
NewNode -> Rlink = NULL;
NewNode -> Rlink = prevNode -> Rlink;
prevNode -> Rlink = NewNode;
NewNode -> Llink = prevNode;
NewNode -> Rlink -> Llink = NewNode;
}