Namu | 나무 개발자 블로그입니다
장고의 디자인 패턴, 모델 by namu

목차
참조
- The MVT Design Pattern of Django
- Django design patterns and Best Practices
- Django model Guideline
- Django Docs: Models and databases
- Manager vs Query Sets in Django
- Two Scoops of Django
장고의 디자인 패턴
소프트웨어 설계 시 자주 발생하는 이슈를 해결하기 위해 고안된 일반적이고 재사용 가능한 방법론을 디자인 패턴이라고 합니다. 웹앱을 구축하기 위해 설계된 장고는 MVT 디자인 패턴으로 구성되었습니다.
MVT 와 유사한 MVC 패턴은 모델(Model), 뷰(View), 컨트롤러(Controller) 로 구성되어 있는데, 모델은 DB 의 데이터를 활용해 비즈니스 로직을 수행하고 뷰는 사용자에게 보여지는 화면과 데이터를 나타내며 컨트롤러는 사용자의 요청을 받아 모델과 뷰를 적절하게 다룹니다.
이와 유사하게 모델(Model), 뷰(View), 템플릿(Template) 으로 구성된 MVT 패턴에서 주목할 점은 MVC 의 뷰 역할을 템플릿이, 컨트롤러 역할을 뷰가 수행한다는 점입니다.
이 두 디자인 패턴은 사실상 명칭만 다르지 기능적으로 완전히 동일하다고 봐도 무방합니다.
결국 장고에서 사용자에게 보여지는 부분은 템플릿이, 사용자의 요청을 받아 모델을 이용해 적절한 결과를 반환하는 기능은 뷰가 수행한다는 사실을 기억하시기 바랍니다.
이러한 구조에서 주요한 이슈 중 하나는 프로젝트의 비즈니스 로직을 어디에 어떻게 구현하는가 하는 것입니다.
MVT 에서 모델 부분에 비즈니스 로직을 구현하는 것이 일반적이나, 도메인마다 굉장히 상이한 장고 구현체들을 살펴보면 항상 그렇지만은 않습니다.
또한 규모가 큰 프로젝트에서 어떤 비즈니스 로직은 점점 복잡해져서 하나의 모델이 너무 무거워지거나 모델 간 의존성이 발생할 위험이 있습니다. 이는 보통 유지보수와 테스트의 기술적 부채로 이어집니다.
이러한 문제점으로 유추되는 사실은, 상대적으로 고정적인 템플릿이나 뷰보다 모델을 적절하게(결합도는 낮추고 응집도는 높이는 방식으로) 설계하는 것이 중요하다는 것입니다.
관련해서 장고의 디자인 철학을 요약한 이 글을 살펴보십시오.
[번역] 장고 모델 가이드라인
이전 글의 장고 모델을 활용한 모범 사례에서는 모델을 활용하는 일반적인 노하우들을 설명했습니다. 이번 장고 모델 가이드라인 번역글에는 다년간의 장고 프로젝트 경험을 통해 다양한 구현 사례들을 경험한 저자의 실용적인 노하우가 담겨 있습니다.
대표적으로 저자는 널리 통용되는 ‘비즈니스 로직은 장고 모델에 구현한다’ 는 규칙은 Fat Models 을 만들기 때문에 적절치 않다고 강하게 비판합니다.
그 자세한 이유와 함께 장고 모델 설계에 관한 저자의 노하우들을 설명할텐데, 이를 무비판적으로 수용하기보단 보완할 점이 있는지 생각하면서 살펴봅시다.
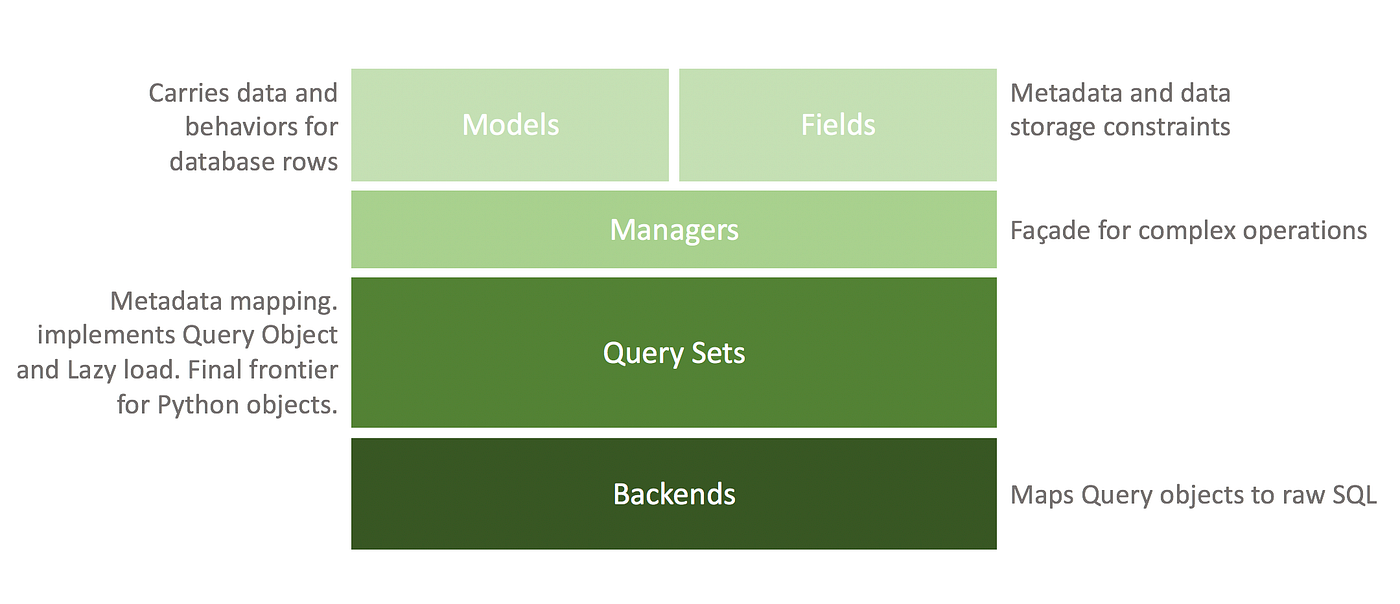 image by
Jair Verçosa’s post of medium
image by
Jair Verçosa’s post of medium
(장고 모델의 구조. 만약 부가적인 비즈니스 로직이 구현된다면 Managers 부분이 그나마 나아 보인다.)
거대 모델(Fat Models)이 나쁜 이유
(1) 시간이 지남에 따라 너무 많은 의존성을 생성함
대부분의 “비즈니스 로직” 플로우를 실제로 살펴보면 로직을 시작한 모델과 끝내기 위해 호출하는 모델의 메서드나 함수가 서로 다릅니다. 이는 어플리케이션의 핵심을 차지하는 모델에 대한 불필요한 의존성을 생성합니다.
이러한 컴포넌트 간 결합은, 다른 모델에서 무언가 변경사항이 발생하면 해당 모델 내 메서드 명세의 수정 혹은 추가로 발생 가능한 사이드 이펙트 핸들링과 같은 코드의 변경을 강제합니다.
그럴 이유가 전혀 없음에도 불구하고, 시간이 지남에 따라 추적할 수 없는 연결고리가 계속해서 생성될 것입니다.
(2) 테스트가 어려움
모델이 커다란 플로우를 가지고 있다면 틀림없이 테스트 또한 커질 것이고, 이는 많은 양의 테스트 데이터를 요구할 것입니다.
메서드를 단순하게 유지하고, 의존성을 회피하며, 테스트를 간단하게 작성하십시오.
(3) Single Responsibility Principle(SRP) 규칙을 위반함
거대 모델은 특정 클래스가 담당해야 하는 역할을 더 추가하도록 만들 것입니다. 저는 프로젝트에서 사람들이 “Customer” 와 같은 모델이 이메일과 공지사항을 전송하도록 만드는 것을 자주 목격했습니다.
모델이 담당하는 역할은 이메일을 전송하는 것이 아니라 “Customer” 데이터를 다루는 것입니다.
(4) 당신을 게으르게 함
이상하게 들리겠지만, 이 말은 당장의 편리함을 위해 어떤 모델에 또다른 메서드를 추가하게 되기 매우 쉽다는 의미입니다. 이러면 원하는 동작을 수행하도록 하기 위해 또다른 함수나 클래스를 임포트할 필요가 없게 됩니다.
결과적으로 당신의 클래스는 어떤 모델이라기보다는, 이러한 모든 것들을 수행하는 파사드(facade)처럼 동작하게 됩니다. 한번 이것을 테스트해 보십시오. 악몽입니다.
모델 설계시 고려할 5가지 노하우
(1) 모델은 자신이 가진 데이터만을 다룸
장고 모델은 Active Record pattern 의 구현체입니다. (Active Record pattern: 관계형 데이터베이스의 테이블이나 뷰와 같은 객체에 매칭되어, 이것의 데이터를 직접적으로 다루는 함수를 제공하는 클래스 패턴) 이것은 오직 자신의 데이터만을 다루는 로직을 포함해야 합니다.
(2) 모델에는 플로우가 아니라 행위만을 추가할 것
장고 모델은 파이썬 클래스일 뿐입니다. 객체지향 프로그래밍에서, 객체의 상태(status)는 이것의 행위(behaviors)에 의해서만 변화되어야 합니다. 이러한 경우 실제로 상태를 검사한 뒤 변화시키는 메서드만을 추가합니다. 이에 따라 상태가 손상되는 위험이 줄어듭니다.
Customer 라는 모델이 있다고 가정해 봅시다.
from django.db import models
class Customer(models.Model):
name = models.CharField(max_length=90)
active = models.BooleanField(default=True)
work_email = models.EmailField()
personal_email = models.EmailField(null=True, blank=True)
만약 특정 고객을 비활성화시키고자 하는 경우, 모델에 해당 행위(behavior)를 추가하는 방법이 있습니다.
from django.db import models
class Customer(models.Model):
name = models.CharField(max_length=90)
active = models.BooleanField(default=True)
work_email = models.EmailField()
personal_email = models.EmailField(null=True, blank=True)
def deactivate(self):
self.active = False
self.save(update_fields=['active'])
다음으로 work_email 이 personal_email 과 다른지 확인할 필요가 있다고 가정해 봅시다. 이 경우 저라면 다음과 같이 할 것입니다.
from django.db import models
class Customer(models.Model):
name = models.CharField(max_length=90)
active = models.BooleanField(default=True)
work_email = models.EmailField()
personal_email = models.EmailField(null=True, blank=True)
def deactivate(self):
self.active = False
self.save(update_fields=['active'])
def set_personal_email(self, email):
if self.work_email == email:
raise ValueError(
"Personal email and work email are equal"
)
self.personal_email = email
self.save(update_fields=['personal_email'])
위 코드에서는 행위 메서드들이 각 목적에 따라 호출되는 동안 항상 상태가 일정하게 유지되도록 하고 있습니다.
당신이라면 굳이 이렇게 할 필요 없이 클래스의 외부에서 save 메서드가 호출되도록 할 수 있겠지만, 제가 한 방식은 데이터가 유지되고 있는 위치나 상태 유지가 어떻게 이루어지고 있는지 정확히 알 수 있습니다.
(3) 상태(state)를 직접적으로 변경하는 것을 피할 것
클래스의 상태(state)를 직접적으로 변경하지 마십시오. 항상 (상태값 체크 등이 포함되는) 행위(behaviors)를 사용하십시오. 이것은 중요합니다!
상태를 서로 다른 많은 장소에서 변경하는 것은 커다란 어플리케이션에서 특정 객체를 추적하기 정말 힘들게 만듭니다.
(4) 의존성을 피할 것
특정 모델에서 다른 모델이나 클래스를 호출하도록 하지 마십시오. 이때 필요한 것은 플로우(flow)로, 필요한 모델들을 호출하고 원하는 플로우를 수행하는 함수를 만들 수 있습니다.
def create_customer(self, name, work_email, personal_email=None):
customer = Customer.factory(
name=name,
work_email=work_email,
personal_email=personal_email,
)
WelcomeEmailSender.send(customer.name, customer.work_email)
return customer
(5) 모델 매니저(Model Managers)를 사용하도록 만들 것
모든 장소에 걸쳐서 쿼리를 수행하는 경우를 피해야 합니다. 모델 매니저에 이러한 내용을 구현하면 더 수월한 테스트가 가능하며 오직 한 곳에서 변경할 수 있습니다.
from django.db import models
class CustomerManager(models.Manager):
def find_by_email(self, email):
return self.filter(
models.Q(work_email=email) |
models.Q(personal_email=email)
)
def find(self, id):
return self.get(pk=id)
class Customer(models.Model):
name = models.CharField(max_length=90)
active = models.BooleanField(default=True)
work_email = models.EmailField()
personal_email = models.EmailField(null=True, blank=True)
objects = CustomerManager()
...
저자의 의견 돌아보기
(1) 고정된 기능이라면
위 번역글에서 저자는 이론적으로 모델의 목적에 충실한 모듈을 설명하고 있습니다.
하지만 실제 프로젝트를 진행하다보면 도메인의 코드 스타일에 따라
‘고객등록 후 Welcome 이메일을 전송하는 것’과 같이 거의 완전히 결합된 하나의 로직은 모델쪽 커스텀 매니저에 넣을 수도 있습니다.
이렇게 되면 해당 기능을 위한 별도의 함수를 생성할 필요가 없습니다.
# In models.py
class CustomerManager(models.Manager):
...
def create_and_send_welcome_email(self, name, work_email, personal_email=None):
assert name is not None
assert work_email is not None
customer = super().create(
name=name,
work_email=work_email,
personal_email=personal_email,
)
WelcomeEmailSender.send(name, work_email)
return customer
class Customer(models.Model):
...
objects = CustomerManager()
...
# In views.py
class SignUpView(View):
def get(self, request):
return render(request, 'users/signup.html')
def post(self, request):
name = request.POST.get('name')
work_email = request.POST.get('work_email')
personal_email = request.POST.get('personal_email')
Customer.objects.create_and_send_welcome_email(name, work_email, personal_email)
return render(request, 'users/login.html')
저자의 노하우가 원리에 더 부합한 것이 사실입니다. 하지만 문제는 여러 모델이 결합된 로직이라면 전부 다 함수로 분리해야만 하느냐는 것입니다. 위와 같은 경우 모델이 다소 무거워지더라도 조금 더 나은 생산성을 확보할 수 있습니다.
이는 프로젝트에 지향점에 따라 선택할 수 있는 부분이라는 점을 꼭 기억하시기 바랍니다.
(2) 플로우의 구현은?
플로우는 비즈니스 로직입니다. 저자는 플로우를 request 에서 response 에 이르기까지 이루어지는 모든 과정이라고 설명합니다. 이것은 어디에 구현하면 좋을까요? 장고 구조 중에서 views.py, models.py, 혹은 forms.py 일까요?
저자는 MVT 구조에다 Clean Architecture 의 Robert C. Martin 이 주장한 Use Case (U) 레이어를 추가하는 방법을 제시합니다. ( Business Logic in Django projects)
Use Case 란, 어플리케이션이 본래 의도한 로직에만 집중한 독립적인 컴포넌트입니다. 이를 위해 시스템의 user-facing 레이어 및 여러 모델들과 관계합니다.
U — Usecase: The goal of an use case is to concentrate the business logic for the operations of an application. It knows all Models that should be part of the flow and knows the API of those models. It also orchestrate all the side-effects and therefore can make the use of other use cases.
일반적인 웹앱 시스템에서 개발자는 웹앱의 구조 자체에 과도하게 관심을 갖는 경우가 많지만, 결국 중요한 것은 그것이 어떤 일을 하느냐입니다.
예를 들어 어플리케이션에서 새로운 사용자가 등록될 때 중요한 것은 모델, 뷰, 템플릿의 구조보다 사용자 데이터를 검증하고, 저장하고, 웰컴 메시지를 전송하는 일련의 비즈니스 로직입니다.
Use Case 는 구조적으로 어떤 형태가 되어야하는지 강제되지 않습니다. 따라서 저자는 register_user_account.py 컴포넌트를 별도로 생성하고 User 모델과 WelcomeEmail 클래스를 임포트하여 로직을 구현합니다.
이렇게 플로우에만 집중한 Use Case 를 생성하면, 오히려 뷰나 모델, 템플릿은 각 본연의 기능에만 충실하게 되는 효과가 있으며, 객체지향의 아이디어에 맞게 비즈니스 객체를 의미하는 각 모델들의 결합도는 줄고 응집도는 높아집니다.
Two Scoops of Django 는 거대 모델(Fat Models)이 신의 객체(god object) 수준으로 폭발하는 것에 대한 위험성을 강하게 경고합니다.
이런 안티 패턴의 결과로 모델 클래스가 수백, 수천, 심지어는 수만 줄의 코드가 되어 버리기도 한다. 코드의 어마어마한 크기와 복잡성으로 말미암아 이런 신의 객체들은 이해하기도 어렵고 테스트하거나 유지 보수하기에도 매우 어려워진다.
실제로 프로덕트를 운영할 때 시간이 흐름에 따라 비즈니스 로직의 양이 폭발적으로 증가하는 것을 흔히 볼 수 있습니다. 이 때 객체지향의 개념을 이해하고 초기부터 MVT+U 패턴에 충실한 코드를 작성해 나가면 약간의 단기적인 귀찮음을 감수하면서 매우 커다란 생산성과 유지보수의 용이함을 얻을 수 있습니다.
Two Scoops of Django 는 거대 모델을 야기하는 플로우의 핵심 내용을 모델 행동(Model Behavior)과 헬퍼 함수(Helper Function)로 구분합니다.
정리
거대 모델(Fat Models)은 점점 많은 의존성을 생성하고, 테스트가 어렵고, SRP(Single Responsibility Principle) 를 위반하도록 합니다.
이를 지양하기 위해 모델 고유의 행위(model behavior)와 플로우의 관점에서 모델의 상태변화와는 무관한 헬퍼 함수(stateless helper function)의 개념을 나눠서 구성하는 MVT+U(UseCase) 어플리케이션 디자인 패턴을 사용하도록 합시다.
Use Case 는 장고 구조에서 정형화된 형식은 없습니다. 또한 모든 플로우(아주 작은 비즈니스 로직까지)를 모듈화시킬 수도 있겠지만, 프로젝트의 일정이나 비용, 생산성 등의 환경에 따라 Fat Models 의 부정적 측면을 최대한 억제하면서 유연성을 마련할 수 있을 것입니다.
나아가 특정 비즈니스 로직이 생각보다 거대하고 범용적이라면 별도의 프로젝트 수준으로 분리할 수도 있을 것입니다. (MSA 의 경우)
사용자 관점의 도메인 혹은 프로젝트별 합의에 따라 비즈니스 로직의 Use Case 구현에 대한 코드 컨벤션을 마련하여 사용하도록 합시다.
- 추가로 살펴볼 내용
- Two Scoops of Django 에서는 비즈니스 로직을 가급적 모델에 두고, 아니라면 forms.py 에 두라고 함
- Django docs https://docs.djangoproject.com/en/4.0/#the-view-layer 에서는 사용자 request 에 따른 logic 을 encapsulate 하는 views 를 추천함