Namu | 나무 개발자 블로그입니다
[02] AWS 자격증 취득하기: SA - Associate by namu

목차
시리즈
참조
- AWS: training page of SA(Solutions Architect)
- 인프런 강의(코드바나나님): AWS Certified Solutions Architect - Associate 자격증 준비하기
들어가며
이전글로부터 이어집니다.
인프런 AWS Certified Solutions Architect - Associate 자격증 준비하기 강의를 참조했습니다.
“[실전]” 키워드가 달린 부분은 실전문제풀이 이후 출제된 문제 관점에서 개념을 추가로 정리한 내용입니다.
개념 정리
데이터 분석 서비스
데이터 분석 서비스 내용은 시험에서 개념적으로 이해하고 있으면 됩니다.
(1) Amazon Athena 는 표준 SQL 을 사용해 S3 에 저장된 데이터를 분석하는 쿼리 서비스입니다. CSV, JSON, ORC, Avro 또는 Parquet 등 다양한 데이터 형식을 지원하며, S3 에서 직접 가져오므로 비용 효율적입니다.
- Athena 연합 쿼리: CloudWatch Logs, DynamoDB, DocumentDB, RDS, JDBC 호환 관계형 DB(MySQL, PostgreSQL 등) 데이터 원본에 대해 쿼리 수행 가능
- Amazon QuickSight 와 통합하여 쿼리된 데이터를 시각화할 수 있음
(2) Amazon Redshift 는 데이터 웨어하우스(의사결정을 위한 정보의 집합) 서비스입니다.
- 데이터 웨어하우스: 여러 소스로부터 얻은 구조화/반구조화(정형화/반정형화)된 대량의 데이터를 중앙 집중화 및 통합하여 자체 분석 기능을 통해 비즈니스적 통찰력을 도출합니다.
- 데이터 로드 대상: S3, RDS, DynamoDB, Kinesis Data Firehose, EMR, Glue, Data Pipeline 및 EC2, 온프레미스의 모든 SSH 지원 호스트, 다양한 데이터 소스
- 데이터 분석 주체: 비즈니스 애널리스트, 데이터 엔지니어, 데이터 사이언티스트 및 의사 결정권자가 비즈니스 인텔리전스(BI) 툴 사용
(3) Amazon OpenSearch Service(Amazon Elastic Search Service) 는 분산 검색 및 분석 툴로, 오픈소스인 Elasticsearch 에서 파생되었습니다. 이 서비스는 로그 분석과 실시간 애플리케이션 모니터링 및 웹사이트 검색 등을 쉽게 수행할 수 있도록 합니다.
- 다양한 소스에서 스트리밍 데이터를 OpenSearch Service 도메인으로 로드
- CloudWatch Logs 나 Kinesis Data Firehose 소스 로드를 기본으로 지원함
- S3, Kinesis Data Streams, DynamoDB 소스는 Lambda 함수의 이벤트 핸들러를 사용해 로드함
(4) AWS QuickSight 는 클라우드 기반의 비즈니스 인텔리전스(BI) 시각화 도구로 의사결정을 돕기 위해 대시보드, 그래프 등의 형태로 데이터 분석결과를 제공합니다.
- CSV 및 Excel 파일 업로드, Salesforce 와 같은 SaaS 애플리케이션 연결, SQL Server, MySQL/PostgreSQL 온프레미스 DB 연결, Amazon Redshift, RDS, Aurora, Athena, S3 등등 데이터 소스 검색
(5) AWS Glue 는 데이터 분석을 위한 ETL(Extract, Transform and Load) 서비스입니다. 다양한 소스에서 데이터를 검색 및 추출, 데이터 강화, 정리, 정규화 및 결합, 데이터베이스, 데이터 웨어하우스 및 데이터 레이크에 데이터 로드 및 구성 등의 여러 작업을 포함합니다.
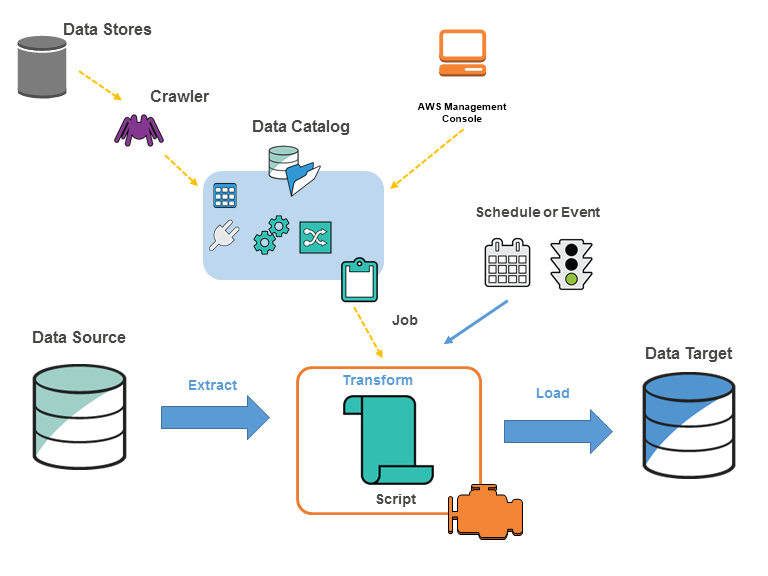
(6) AWS Lake Formation 은 데이터 레이크 서비스로, Redshift 가 정형화/반정형화된 데이터를 다룬다면 이것은 구조화되지 않은 데이터까지 모든 유형의 대량의 데이터를 다루는 중앙 집중식 저장소입니다.
(7) Amazon EMR(Elastic MapReduce) 는 클라우드 빅데이터 플랫폼으로 Hadoop 클러스터를 손쉽게 생성하도록 합니다.
- MapReduce 는 분산 병렬처리 컴퓨팅 모델로 머신러닝이나 빅데이터 처리 등에 사용됨
- 데이터 처리를 위한 EMR 클러스터(수십~수백 대의 EC2 인스턴스)를 자동으로 구성하고 확장 및 축소하는 기능을 수행
애플리케이션 통합
(1) Simple Queue Service(SQS) 는 메시징 큐 서비스로 애플리케이션 간의 느슨한 결합을 제공하기 위해 사용됩니다. 느슨한 결합의 활용방식은 consumer 가 큐 대기열로부터 메시지를 Polling 방식으로 얻어와 순차적으로 처리하는 것입니다.
- 대기열: producer 는 처리가 필요한 메시지를 대기열에 올려놓습니다.
- 표준대기열: 순서와 상관없이 메시지가 전달되며, 가끔 2개 이상의 복사본이 전달될 수 있음 (ex. 파일 업로드, 데이터베이스 항목 추가)
- FIFO대기열: 선입선출! (ex. 쇼핑몰 주문 결재처리 후 배송처리)
- DLQ, Dead Letter Queue: 배달 못한 편지 대기열로, 일정 횟수 이상 시도 후 처리되지 못한 메시지는 SQS 에서 DLQ 로 이관됨
- Visibility Timeout(제한 시간 초과, 표시 제한 시간): consumer 의 메시지 수신 이후 완료 응답 신호를 기다리는 SQS 의 기능으로
기본 30초로 세팅됨 (최소 0초 최대 12시간)
- 연결 또는 앱 문제로 메시지를 다시 수신하는 경우가 있기 때문에 SQS 는 수신된 메시지를 자동 삭제하지 않음
- Visibility Timeout 기간 동안 남아있는 해당 메시지를 다른 consumer 가 처리하지 못하도록 하여 중복 처리 방지
- Short Polling VS Long Polling: 짧은 폴링은 메시지가 비어 있어도 consumer 의 메시지 요청을 즉시 반환하는 방법이고,
긴 폴링은 메시지가 빈 경우 메시지 수신 대기시간(Receive message wait time)동안 기다렸다가 반환하는 방법
- 대기시간은 1초부터 최대 20초까지 설정 가능하며, 짧은 폴링에서 대기시간은 0초
[실전] 이벤트 데이터를 생성하는 서비스에서, 이벤트 데이터를 수신하는 대로 처리 / 데이터는 처리 전반에 걸쳐 유지되어야 하는 특정 순서로 작성된다고 할 때, 운영 오버헤드를 최소화하는 솔루션은?
- (O) 생성된 메시지를 손실 없이 처리해야 하므로 SQS 메시지 큐를 사용하고, 순서성이 중요하므로 FIFO 대기열을 생성함
- (X) SQS 표준 대기열을 사용하면 순서성 보장이 안되고 가끔 2개 이상의 복사본이 전달될 수 있으므로 부적절
- (X) SNS 주제를 생성하여 Lambda 함수나 SQS 가 구독하게 하는 방식은 순서성 보장이 안되므로 부적절
[실전] 마이크로 서비스로 구성된 환경으로, API Gateway 와 함께 클라이언트 지향 API 를 사용하고 EC2 인스턴스에서 호스팅 되는 여러 내부 서비스를 사용하여 사용자 요청을 처리합니다. API 는 예측할 수 없는 트래픽 급증을 지원하도록 설계되었지만 내부 서비스가 급증하는 동안 일정 기간 동안 압도되고 응답하지 않을 수 있습니다. 솔루션 설계자는 내부 서비스가 응답하지 않거나 사용할 수 없게 될 때, 오류를 줄이는 보다 안정적인 솔루션을 설계해야 합니다.
- API 와 EC2 내부 서비스 간 디커플링 문제. 내부 서비스 응답 불가 상황을 가정하여 오류를 줄이는 안정적인 방법을 물어보고 있다..!
- Auto Scaling 을 적용한다 해도 서버가 응답하지 않거나 사용할 수 없게 되어 오류가 발생하는 현상을 해결할 수는 없음
- 해결: SQS 메시지 대기열을 사용하여 사용자 요청을 저장하고, 각 내부 서비스 인스턴스가 폴링하게 한다. 이렇게 하면 인스턴스 상황에 따라 응답까지 지연될 수는 있지만 요청 메시지는 보존되어 오류의 가능성은 줄어든다
[실전] 비디오 변환 어플리케이션은 프리 티어와 유료 티어 두 가지 타입이 제공됩니다. 유료 계층 먼저 비디오를 변환한 다음 프리 계층 비디오를 변환합니다. 가장 비용 효율적인 솔루션은,
- 해결: 2 개의 표준 SQS 대기열을 생성하여 각 용도로 사용
- (X) SQS FIFO 대기열은 표준 대기열보다 비싸므로 비용 효율적이지 않음. 문제에는 순서성에 대한 언급도 없음
(2) Simple Notification Service(SNS) 는 AWS 의 메시징 서비스입니다. 기본적으로 Publishers 가 Topic 을 생성하고 Subscribers 에게 메시지를 전송하는 방식입니다.
- SNS 의 Topic 은 Push 방식으로 메시지를 전송하며, 전송 관계는 A2A 혹은 A2P 로 이루어짐
- 메시징은 문자, 이메일, S3 버킷 이벤트, CloudWatch 이벤트 등으로 설정 가능
- Subscriber 는 A2A: SQS, Lambda, HTTPS, Kinesis Data Firehose / A2P: SMS, Mobile push, Email
- SNS + SQS Fan Out 모델: AWS 의 메시징 서비스를 조합해 Push 및 Polling 모델 구성 가능

- SNS 는 Publisher 에 의해 Topic 에 메시지가 생성되면 바로 push 하고(Fan Out 이라고 함), Subscriber 로 등록된 SQS 는 생성된 메시지를 대기열에 올려 적절히 소비되도록 함
- SNS FIFO Topic: SNS Topic 생성 시 FIFO 방식으로 지정할 수 있음. 정확한 순서대로 메시지 push.
Fan Out 모델이라면 정확한 순서대로 SQS 대기열 구성

[실전] 2단계 주문을 위한 애플리케이션 설계 시, 첫 번째 단계는 동기적이며 짧은 대기 시간으로 사용자에게 반환되어야 합니다. 두 번째 단계는 시간이 더 오래 걸리므로 별도의 구성 요소에서 구현됩니다. 주문은 정확히 한 번 그리고 접수된 순서대로 처리되어야 합니다.
- 해결: SNS + SQS 두 단계로 분리하여 SNS 를 통해 짧은 대기시간 반환, SQS FIFO 대기열을 사용해 주문을 순서대로 처리
(3) Kinesis 는 실시간 스트리밍 데이터를 손쉽게 수집, 처리 및 분석하는 서비스입니다. 데이터가 수집된 후에 처리를 시작하는 것이 아닌 데이터가 수신되는 대로 처리 및 분석하는 것이 특징입니다.
- 수집대상: 비디오, 오디오, 앱 로그, 웹사이트 클릭스트림 및 IoT 텔레메트리 데이터와 같은 실시간 데이터
- 서비스 유형:
- Kinesis Data Streams: 수집(캡쳐), 저장 및 처리. 스토리지가 있음!
- Kinesis Data Firehose: 스트리밍 ETL. AWS 데이터 스토어에 로드. 스토리지가 없고 분석도구로 보냄! 거의 실시간 분석!
- Kinesis Data Analytics: SQL 또는 Apache Flink 로 데이터 스트림 분석
- Kinesis Video Streams: 비디오 스트림을 수집, 저장 및 처리
[실전] 점수 업데이트를 스트리밍한 다음 리더보드에 결과를 게시하는 모바일 게임이 존재할 때, 대규모 트래픽 급증을 처리할 수 있는 솔루션 설계가 필요합니다. 업데이트를 수신 순서대로 처리하고 처리된 업데이트를 고가용성 데이터베이스에 저장하되 관리 오버헤드 최소화가 요구될 때 적절한 솔루션은,
- 해결: 스트리밍 데이터를 수신 순서대로 처리하기 위해 Kinesis Data Streams 사용하고 고가용성 및 관리 오버헤드 최소화를 위해 Lambda 를 활용한 업데이트 데이터 처리, 처리된 업데이트를 DynamoDB 에 저장
- (X) ASG 및 RDS 다중 AZ DB 인스턴스 사용은 상대적으로 관리 오버헤드가 들어가므로 부적절
- (X) SQS 는 업데이트 순서대로 처리가 가능하나 스트리밍 데이터 처리 솔루션이 아님. SNS 도 마찬가지
(4) Amazon MQ 은 Apache ActiveMQ 및 RabbitMQ 용 관리형 메시지 브로커 서비스입니다. (JMS, NMS API / AMQP, STOMP, MQTT, WebSocket 메시징 프로토콜)
- 활성(Active)/대기(Standby) 브로커 배포모드 지원하여 고가용성 및 장애조치 가능
- 사용예
- 클라우드 기반 애플리케이션 구축시 » SNS, SQS 메시지 서비스(스케일링, 고가용성, 성능 및 기능 면에서 우월)
- 기존 온프레미스 애플리케이션 혹은 마이그레이션 시 코드 변경 최소화 » Amazon MQ 로 호환
(5) API Gateway 는 개발자가 API 를 생성, 게시, 유지관리, 모니터링 및 보안 유지를 할 수 있게 하는 서비스입니다. 백엔드 API 서버와 연결하여 REST API 를 제공합니다. (Websocket API 도 지원)
- API 엔드포인트 유형: API 가 호출되는 클라이언트의 출처에 따라 유형 선택
- 엣지 최적화 API 엔드포인트: 지리적으로 분산된 클라이언트에게 최적인 엔드포인트. AWS 리전 전체에서 각 클라이언트 API 요청은 가장 가까운 CloudFront POP(Point of Presence) 로 라우팅됨. API Gateway REST API 의 기본 엔드포인트임
- 리전 API 엔드포인트: 동일 리전의 클라이언트를 위한 엔드포인트로, API 수요가 큰 소수의 클라이언트에게 낮은 오버헤드로 서비스를 제공할 때 사용. 이 엔드포인트에서 API 요청은 CloudFront 배포판을 거치지 않고 리전별 API Gateway 에 직접 지정됨
- 프라이빗 API 엔드포인트: VPC 종단점(엔드포인트)을 사용해서 VPC 에서만 액세스할 수 있는 API 엔드포인트. 이 때 이 엔드포인트는 사용자가 VPC 에서 만든 엔드포인트 네트워크 인터페이스(ENI)임.
[실전] 퍼블릭 API 의 경우, 권한이 없는 사용자의 무분별한 요청(트래픽)을 차단하기 위해서는 a. 정품 사용자와만 공유하는 API 키를 사용하여 사용 계획을 만들거나, b. AWS WAF 규칙을 구현하여 악의적인 요청을 대상으로 하고 이를 필터링하는 작업을 트리거합니다.
[실전] 기존의 분석 플랫폼에서 다량의 데이터 분석을 위한 데이터 포인트를 새로 구성하여 다층 아키텍쳐의 일부로 사용하고자 합니다. 이 때 데이터 포인트는 REST API 에서 액세스 할 수 있어야 합니다.
- 해결: REST API 를 위해 API Gateway 를 사용하고, 백단에 데이터 포인트로 Amazon Kinesis Data Analytics 를 함께 배치
- (X) 데이터 포인트로 Lambda 는 부적절.
[실전] 다계층 애플리케이션 구성 시 최소 요구 사항은 고가용성, 확장성 및 피크 시간 동안의 지역적(regional) 짧은 지연 시간입니다. 자체 인프라 관리를 피하고자 하며 애플리케이션의 API 를 사용하여 밀리 초 지연 시간으로 데이터를 저장하고 검색합니다.
- 조건이 좀 많다. 정리하면,
- (1) 고가용성, 확장성
- (2) 자체 인프라 관리 X
- (3) 애플리케이션 API 사용
- (4) 지역적 짧은 지연 시간
- (5) 밀리 초 지연 시간으로 데이터 처리
- 해결: 1번과 2번 조건은 서버리스인 Lambda 컴퓨팅 및 DynamoDB 를 사용. DynamoDB 는 5번 조건도 만족. 3번을 위해 API Gateway 를 사용하되, 엣지 최적화 API 엔드포인트를 지정(4번 조건)
- (X) 자체 인프라 관리가 필요한 RDS 나 EC2 ASG 및 EBS 등의 사용은 부적절. RDS 는 밀리 초 지연 시간에도 부적절.
(6) AWS Step Functions 는 AWS 서비스들을 시각적으로 연결하여 구축하는 Workflow 서비스이고, Amazon AppFlow 는 SaaS 애플리케이션과 AWS 간에 안전하게 데이터를 전송할 수 있게 하는 서비스입니다.(API 커넥터 구축)
보안 및 자격증명
(1) AWS Cognito 는 애플리케이션에 대한 로그인 및 인증을 제공하는 서비스로, 웹과 모바일 앱에세 빠른 사용자 가입, 로그인 및 액세스 제어 기능을 제공합니다. 애플, 구글, 페이스북 등의 계정과 통합 가능합니다.
- 사용자 풀(User Pool): 사용자 계정 정보가 있는 장소
- 자격증명 풀(Identity Pool): 액세스 권한 정보가 있는 장소
- 앱 또는 웹에서 로그인을 시도하면 사용자 풀에서 토큰을 전달하고, 그것으로 자격증명 풀에 인증을 요청하면 인증서를 반환하여 AWS 리소스에 접근하는 방식
(2) AWS SSO(Single Sign On) 는 중앙에서 관리하는 하나의 계정으로 여러 애플리케이션에 로그인하는 기능입니다. AWS Organization, MS Active Directory, SAML 2.0 과 통합 가능합니다.
(3) KMS(Key Management System) 는 AWS 에서 암호화 키를 생성하고 관리하는 서비스입니다. 대부분의 AWS 서비스에서 암호화는 KMS 와 관련되어 있습니다.(EBS 볼륨 암호화, S3 객체 암호화, RDS 데이터 암호화 등)
- KMS 의 기능
- 암복호화를 위한 키(Key)를 주기적으로 자동 교체하는 기능
- CloudTrail 과 통합하여 모든 키 사용에 관한 감사 로그 제공
- 키 유형: 고객 관리형 키(CMK), AWS 관리형 키(AWS Managed Keys), AWS 자체 키(AWS Owned Keys)
- 다중 리전 키(Multi Region Keys): 기본적으로 KMS 키는 단일 리전에서만 공유하나, 다중 리전 키는 여러 리전에서 동일한 키를 공유합니다. Primary 리전에 원본 키를 생성하고 다른 리전에 replica 를 생성. DynamoDB 글로벌 테이블 및 DynamoDB 암호화, 멀티 리전의 복제된 S3 버킷 암호화 등에 사용 가능
- CloudHSM: KMS 가 소프트웨어 방식의 암호화라면 CloudHSM 은 하드웨어 암호화 장비를 활용한 암호화 방식. 키 관리는 사용자(클라이언트)가 해야 하므로, SSE-C(고객 제공 키) 관리에 적합합니다.
(4) Secrets Manager 는 보안 정보(자격증명)를 중앙 집중식으로 저장, 검색, 액세스 제어, 교체, 감사 및 모니터링하는 서비스입니다. 보안 정보에는 DB 자격증명, 온프레미스 리소스 자격 증명, SaaS 애플리케이션 자격 증명, 타사 API 키 및 SSH 키 등이 있을 수 있습니다.
- 보안 정보 유지방법
- 사용자의 KMS 키를 사용해 보안 정보를 암호화
- 사용자는 IAM 정책을 사용하여 보안 정보에 대한 액세스 제어
- 사용자가 보안 정보를 검색하면 Secrets Manager 가 해당 보안 정보를 복호화하여 TLS 를 통해 안전하게 로컬 환경으로 전송
- 보안 정보 자동 교체 및 관리
- RDS, Redshift, DocDB 와 기본적으로 통합되며, 사용자 대신 데이터베이스 자격 증명을 자동으로 교체
- Lambda 코드와 통합하여 30일, 60일 등의 자격증명 자동 교체 날짜를 지정하여 실행 가능
[실전] 회사에 공통 RDS MySQL 다중 AZ DB 인스턴스에 자주 액세스해야 하는 웹 서버가 여러 대 있습니다. 사용자가 자격 증명을 자주 교체해야 하는 보안 요구 사항을 충족하면서 웹 서버가 데이터베이스에 연결할 수 있는 안전한 방법을 원할 때,
- 해결: 자격 증명을 안전하게 저장 및 자동 교체하는 Secrets Manager 에 자격 증명을 저장, 웹 서버가 Secrets Manager 에 액세스할 수 있도록 필요한 IAM 권한 부여
- (X) Systems Manager 의 OpsCenter 는 운영 문제를 집계하고 진단 및 해결에 도움이 되는 데이터를 제공하는 서비스로 자격 증명의 안전한 보관과는 무관함
(5) AWS Certificate Manager(ACM) 은 리소스에서 사용할 공인 및 사설 SSL/TLS 인증서를 중앙에서 관리 및 배포하는 서비스입니다. 이러한 인증서는 ACM 에서 자동으로 갱신됩니다.
- ACM 은 일반적으로 ELB, CloudFront, API Gateway 에 적용되어 HTTPS 프로토콜을 지원하기 위해 사용됨
(6) Shield 는 AWS 웹 애플리케이션을 DDoS 공격으로부터 보호하는 서비스입니다.
- Shield Standard: 모든 AWS 사용자에 적용되어 있음(무료). SYN/UDP Flood 등 보호
- Shield Advanced: 보다 많은 보호 제공(유료). EC2, ELB, CloudFront, Route53 등에서 정교한 DDoS 보호 제공
(7) Web Application Firewall(WAF) 는 HTTP(OSI 7 Layer) 수준에서 웹 애플리케이션을 보호하는 방화벽입니다. 따라서 ALB, API Gateway, CloudFront 에 적용이 가능합니다.
- WAF 는 Web ACL 을 생성해 rules 을 정의함
- 규칙은 AWS 에서 제공하는 Managed rule groups 또는 사용자 지정 규칙(My own rules and rule groups) 사용
- 악성 IP 주소 차단
- 특정 국가 액세스 제어(차단)
- SQL Injection, Cross-Site-Scripting(XSS) 방어
- 속도기반규칙(Rate-based rules)으로 DDoS 공격 방어 (ex. 5분내 특정 IP 주소로부터 500 번 이상의 액세스가 발생하면 공격으로 간주하고 차단)
- ACL 생성 및 적용
- WAF ACL 생성
- 리소스(CloudFront or Regional resources(ALB, API Gateway, AppSync)) 연결
- 규칙(Rule) 생성 및 Default web ACL action 은 Block 으로 지정
- 생성된 규칙에 대한 CloudWatch metrics 지정
[실전] S3 호스팅 시, 회사의 보안 정책에 따라 모든 웹 사이트 트래픽은 AWS WAF 에서 검사해야 하는 경우, “트래픽 ==> WAF + CloudFront + S3 origin” 형태로 구성
- WAF ACL 은 CloudFront 를 대상으로 생성되고, 모든 트래픽이 이 WAF 를 거치려면 CloudFront 를 거치도록 해야함
- 이를 위해 S3 오리진에 직접적인 액세스는 원천적으로 막아야 함 -> S3 오리진 정책에서 연계된 CloudFront OAI 만 허용하도록 지정해야 함
- (X) WAF <==> S3 origin 직접 설정은 불가능함
- (X) S3 에 보안 그룹(SG) 적용은 불가능함
- (X) CloudFront 에 IP 특정도 불가능함

(8) AWS Firewall Manager 는 AWS Organizations 의 여러 계정과 애플리케이션의 방화벽 규칙을 중앙에서 구성 및 관리할 수 있는 보안 관리 서비스입니다.(중앙에서 관리자 계정)
- 중앙에서 여러 AWS 계정 및 리소스에 걸쳐 있는 VPC 에 대해 WAF 규칙, Shield Advanced 보호, 보안 그룹 및 AWS Network Firewall 규칙 및 AWS Marketplace 서드 파티 방화벽 규칙 및 Route53 Resolver DNS Firewall 규칙을 구성 가능
- 사용 목적에 따라 다중 계정으로 분리된 인프라 구성은 시스템적으로 많은 이점이 있지만,
- 높은 수준의 일관적인 보안 환경을 각각 구축하기 힘들기 때문에, 중앙에서 관리하는 AWS Firewall Manager 서비스는 유용하게 활용 가능함
- 하지만 반대로 모든 리소스에 대한 일괄적인 WAF 규칙 적용은 꼭 필요한 트래픽을 차단하거나 많은 오탐이 발생하는 결과로 이어질 수 있으니 주의
(9) 개념을 알아둡시다!!
- Amazon Cognito: 애플리케이션에 대한 로그인 및 인증을 제공하는 서비스. 애플, 구글, 페이스북 계정 통합 가능
- Amazon GuardDuty: AWS 계정 및 워크로드에서 악의적 활동을 모니터링하고 상세 보안 결과를 제공하는 위협탐지 서비스
- Amazon Inspector: EC2, 컨테이너 등에서 소프트웨어 취약성 검색 및 관리
- Amazon Macie: AWS 에서 민감한 데이터를 기계학습 및 패턴 일치를 활용해 검색하고 보호
[실전] 대기업의 관리자가 회사의 AWS 계정에 대한 암호 화폐 관련 공격(악의적 활동)을 모니터링하고 방지하고자 할 때, Amazon GuardDuty 서비스를 활용합니다.
- GuardDuty 는 탐지 정보를 CloudWatch 등에 제공하고, 관리자는 이를 인지하여 실질적 방어는 별도로 진행하게 됨
관리 및 거버넌스
(1) AWS Organizations 는 글로벌 서비스로 조직에 속한 멤버 계정들의 그룹 및 권한을 중앙에서 관리하는 기능을 제공합니다. 조직관리를 위한 그룹화는 OU(Organization Unit) 단위로 이루어지며, 전체 계정을 관리하는 계정을 마스터 계정(관리계정, Master Account)이라고 합니다.
- OU(Organization Unit): 그룹화를 위한 조직 단위 (ex. Prod OU > HR OU)
- SCP(Service Control Policy): 서비스 제어 정책을 생성 및 적용하여 서비스에 대한 액세스 제어. 개별 계정 혹은 OU 단위로 적용 가능하며, 정책은 상속됨
[실전] 솔루션 설계자는 표준 보안 제어를 유지하면서 AWS Organizations 를 통해 개별 AWS 계정을 개발자에게 제공하려는 회사를 위한 보안 솔루션을 설계하고 있습니다. 개별 개발자는 자신의 계정에 대한 AWS 계정 루트 사용자 수준 액세스 권한을 갖기 때문에 솔루션 설계자는 새 개발자 계정에 적용되는 필수 AWS CloudTrail 구성이 수정되지 않았는지 확인하려고 합니다. 이러한 요구사항을 충족하는 작업은?
- 문제가 요구하는 것은 개발자 계정이 자신의 계정에 대해 루트 수준의 권한을 갖기 때문에 필수 AWS CloudTrail 구성을 수정할 수 있는 가능성을 차단하는 것임
- 해결: CloudTrail 변경을 금지하는 SCP(Service Control Policy, 서비스 제어 정책)을 생성하고 개발자 계정에 연결
- (X) Organizations 를 사용해 중앙에서 관리하므로 개별 IAM 정책을 사용하는 것은 보다 부적절
- (X) 개별 사용자에 SCP 를 적용해야 하므로 루트 사용자에게 적용하는 것은 부적절
(2) CloudWatch 는 모든 리소스에 대한 모니터링 서비스를 제공합니다. 지표(Metrics), 대시보드(Dashboard), 로그(Logs), 경로(Alarms) 기능을 제공합니다.
(3) Amazon EventBridge 는 거의 실시간으로 이벤트를 자동 전송하는 서비스입니다. (EventBridge > Event Bus)
(4) CloudTrail 은 AWS 내에서 수행되는 모든 계정 활동 및 작업에 대한 로그를 기록하는 서비스입니다. 기본적으로 모든 계정에 대해 활성화되어 있으며, 로그는 S3 버킷에 저장 가능합니다.
- 로그파일은 KMS 암호화 가능
- CloudTrail Insight 를 사용하여 비정상적인 활동 감지 가능
- 로그 파일 무결성 검증: S3 버킷으로 로그 전송 이후 유지/삭제/수정 여부 확인 가능
- AWS 계정의 거버넌스, 규정준수, 운영감사, 위험감사에 활용
[실전] 회사 기밀 정보가 포함된 S3 버킷이 존재하고 여기에 CloudTrail 설정이 되어 있으며 감사 로그 사본을 CloudWatch Logs 로 보냅니다. S3 에는 읽기 및 쓰기 데이터 이벤트가 기록되도록 설정되어 있습니다.
- 사건: S3 의 일부 객체가 삭제되었음이 발견되어 삭제한 사람에 대한 정보를 회계 감사자에게 제공해야 함
- 해결: SQL 도구인 Athena 로 CloudTrail Logs 를 쿼리하여 S3 버킷에 대한 호출을 식별
- (X) AWS Config 사용은 부적절함. Config 는 AWS 리소스 구성 변경 사항을 로그로 기록하는 서비스임. 계정의 활동을 감사해야 하는 해당 이슈에는 부적절.
[실전] 회계 시스템 구축 시 회사의 규정 준수 감사를 위해 CloudTrail 을 활성화하여 모든 AWS 활동을 모니터링해야 한다고 합니다. 이 때 (1) 데이터 보안 및 (2) 변경할 수 없는 감사 로그가 최우선이라고 합니다. 적절한 조치는 무엇일까요?
- (1) 데이터 보안: CloudTrail 이 AWS KMS 관리형 암호화 키(SSE-KMS)와 함께 서버 측 암호화를 사용하도록 구성되었는지 여부를 모니터링하는 AWS Config 규칙을 생성합니다. (이번에는 리소스 구성을 확인하기 때문)
- (2) 변경할 수 없는 감사 로그: CloudTrail 로그 파일 유효성(무결성) 검증을 활성화합니다.
(5) AWS Config 는 AWS 리소스 구성 변경 사항을 로그 기록하는 기능으로, 계정의 활동을 감사하는 CloudTrail 과는 차이가 있습니다.
(6) AWS Systems Manager(SSM) 는 시스템 관리를 위한 여러 기능들을 탑재하고 있습니다. 여러 AWS 서비스의 운영 데이터를 중앙집중화하고 AWS 리소스 전체에서 작업 자동화가 가능합니다. (EC2 인스턴스, 엣지 디바이스, 온프레미스 또는 VM 에 SSM Agent 를 설치하여 관리)
- 애플리케이션 관리: Application Manager, AppConfig, Parameter Store
- 변경 관리: Automation, Change Manager, Maintenance Windows
- 노드 관리: Fleet Manager, Session Manager, Patch Manager
- 운영 관리: Explorer, OpsCenter, Incident Manager
(7) (추가) AWS Cost Explorer 는 시간에 따른 AWS 비용과 사용량을 시각화, 이해 및 관리할 수 있는 손쉬운 인터페이스를 제공합니다. 비용 및 사용량 데이터를 분석하는 사용자 지정 보고서를 작성하여 신속하게 시작합니다.
- 모든 계정의 총 비용 및 사용량 분석과 같이 높은 수준의 데이터 분석 혹은 자세한 비용 및 사용량 데이터 분석을 제공하여 추세를 식별하고 비용 동인을 파악하고 이상을 탐지
[실전] 예산 계획의 일부로 경영진이 사용자별로 나열된 AWS 청구 비용 보고서를 원할 때, 솔루션 설계자는 가장 효율적인 방법으로 정보를 얻어 보고서를 제출해야 합니다. 이 때는 Cost Explorer 에서 보고서를 생성 및 다운로드 합니다.
네트워크 관련
(1) Route53 은 AWS 의 DNS(Domain Name System) 서비스로, 퍼블릭 도메인을 구입/이전하여 인스턴스 혹은 ELB 로 라우팅할 수 있습니다. (AWS 내부사용을 위해 프라이빗 도메인도 생성 가능)

- TTL 값(기본 300초)을 설정하여 DNS resolver 로 하여금 해당 도메인의 주소를 캐싱해 두도록 할 수 있음
- 상태 검사(Health Check): 서버의 상태를 모니터링. 상태가 좋지 않으면 장애조치 구성 가능(-> Failover 라우팅)
- 주요 DNS 레코드 유형: DNS 레코드를 통해 트래픽을 도메인에 라우팅하는 방식을 DNS 에 알려줌
- A: 도메인 네임을 IPv4 주소로 라우팅
- AAAA: 도메인 네임을 IPv6 주소로 라우팅
- CNAME: 도메인 네임을 도메인 네임으로 라우팅
- ALIAS: 도메인 네임을 AWS 리소스(ELB, EC2 등)로 라우팅
- MX(Mail eXchanger): 이메일 서버 연동 시 메일의 소유를 확인하기 위한 레코드
- NS(Name Server): 최초 기본 생성, 생성한 DNS 레코드를 가진 DNS 서버를 식별하기 위한 레코드
- SOA(Start Of Authority): 최초 기본 생성, 도메인의 정보와 권한을 가진 레코드
다음은 Route53 레코드 생성 시 지정하는 라우팅 방식입니다.
- 단순 라우팅 방식(Simple): 도메인 네임을 IPv4 주소로 라우팅, 여러 개 설정 시 랜덤으로 주소 반환. 혹은 별칭(alias) 설정으로 AWS 리소스(ELB)로 바로 라우팅 되도록 할 수 있음
- 가중치 기반 라우팅 방식(Weighted): 접속자가 요청하는 횟수의 가중치(%)를 기준으로 라우팅하는 방법. 라우팅 대상별 지정한 가중치에 따라 트래픽이 분산됨
- 지연 시간 라우팅 방식(Latency): 사용자와 가장 짧은 지연시간을 제공하는(가까운) 리전의 Route53 DNS 로 라우팅 (ex. 미국리전에서 요청한 클라이언트는 미국리전의 Route53 DNS 에서 지정한 대상으로 라우팅되도록 지정!)
- 지리적 위치 기반 라우팅 방식(Geo Location): 사용자가 속한 대륙이나 국가를 기준으로 해당되는 Route53 DNS 로 라우팅
- 장애 조치(Failover) 기반 라우팅: 상태 검사(Health Check)를 통해 기본(Primary) 라우팅이 실패하면 보조(Secondary)로 자동 라우팅. 따라서 헬스체크를 이전에 생성해 두어야 함
- 다중 값 응답 기반 라우팅 방식(MultiValue): Route53 DNS 에서 다수의 값을 반환하는 라우팅. 클라이언트에서는 이중 하나로 접속하게 되고, 만약 특정 리소스에 문제가 생기면 DNS 는 그것을 제외하고 반환함(이 때는 헬스체크 활용)
(2) NACL(Network Access Control List) 은 서브넷 레벨에 적용되는 방화벽으로, 허용(Allow) 및 거부(Deny) 규칙을 추가할 수 있습니다. 이는 보안 그룹(SG, Security Group)이 개별 인스턴스나 AWS 리소스에 적용되면서 허용 규칙만 추가할 수 있는 것과는 대조적입니다.
- 서브넷 레벨이기 때문에, 지정된 서브넷 내의 모든 자원에 NACL 의 규칙이 적용됨
- 규칙은 낮은 규칙 번호부터 우선순위로 적용됨 (ex. 90 > 100 > 200)
- 상태 비저장 방화벽(Stateless Firewall)이기 때문에 인바운드 트래픽에 대한 응답은 아웃바운드 규칙을, 아웃바운드 트래픽에 대한 응답은 인바운드 규칙을 따름 (기본 any open 되어있음)
- 외부에서 들어온 요청에 대한 응답 트래픽이 나갈 때 NAT 를 사용하므로, 임시포트 1024-65535 를 열어두어야 함 (기본 any open 되어있음)
(3) NAT Instance 는 EC2 인스턴스에 NAT 기능을 설치하므로 사용자가 직접 구성해야 합니다. 반면 NAT Gateway 는 AWS 가 인터넷향 Public EIP 변환 기능을 제공하므로 추가적인 사용자 구성이 필요 없습니다.
- NAT Gateway 특징
- TCP, UDP, ICMP 등의 프로토콜 지원
- 하나의 EIP 주소만 퍼블릭 NAT 게이트웨이에 연결 가능. 한번 연결된 EIP 를 끊을 수는 없으므로, EIP 교체를 위해서는 새 NAT 게이트웨이와 EIP 를 생성하여 라우팅 테이블을 업데이트 해야함
- 가용성: 각 가용 영역 당 빠르게 NAT 게이트웨이를 구성하여 내부 리소스가 자신과 같은 가용 영역에 존재하는 NAT 게이트웨이에 연결하게 함으로써 고가용성을 만족 (NAT 게이트웨이 하나가 생성되는 퍼블릭 서브넷은 하나의 가용 영역에만 연결됨. 반대로 가용 영역에는 여러 서브넷 가능하나, 개수에 제한이 발생)
- 확장성: 5Gbps 의 대역폭을 지원하며 최대 100Gbps 까지 자동 확장. 초당 백만 개의 패킷을 처리할 수 있으며 초당 최대 천만 개의 패킷을 자동으로 확장. 이 제한을 초과하면 NAT 게이트웨이가 패킷을 삭제하므로, 손실을 방지하기 위하여 여러 서브넷에 별도의 NAT 게이트웨이를 생성하여 리퀘스트를 분할해야 함
(4) 지원되지 않는 구성의 VPC Peering 에는 CIDR Overlapping(동일 블록 중첩) 과 Transitive Peering(전이적 피어링) 이 있습니다. 피어링은 1:1 연결만 가능하기 때문입니다. 따라서 많은 수의 VPC 로 구성된 AWS 인프라를 구축하는 경우, 모든 요소에 피어링을 생성하기보다 Transit Gateway 를 사용하는 것이 복잡성을 줄여 바람직합니다.
(5) AWS PrivateLink 는 VPC 와 AWS 서비스 간 인터넷 연결이 아닌 프라이빗 연결을 제공하는 서비스입니다. 이를 위해 AWS 내부 네트워크를 사용합니다. (EC2 인스턴스와 AWS S3 서비스 간 연결이 대표적) PrivateLink 가 구현되는 기술로는 VPC Endpoint 와 Endpoint Service(AWS PrivateLink) 가 있습니다.
- VPC Endpoint: 인터넷을 통하지 않고 AWS 서비스에 프라이빗하게 연결할 수 있는 VPC 진입점
- 게이트웨이 엔드포인트: 동일 리전의 S3 와 DynamoDB 에 대한 프라이빗 연결 (다른 리전 불가)
- 인터페이스 엔드포인트: 서브넷 IP 주소 범위에서 IP 를 가져와 일종의 AWS 내부 서비스용 네트워크 인터페이스를 생성, 이것을 통해 대부분의 AWS 서비스에 접근 가능
- Gateway Load Balancer 엔드포인트
- Endpoint Service(AWS PrivateLink): VPC 내의 애플리케이션 또는 서비스를 엔드포인트 서비스로 만들어
다른 AWS 계정의 VPC Endpoint 로부터 연결되도록 함. (같은 리전의 서로 다른 VPC 간 서비스적인 내부 연결 생성)
- 물론 VPC 간 연결은 피어링을 사용할 수도 있으나, 피어링은 1:1 연결이므로 VPC 구성이 많은 경우 일일히 생성해줘야(요청, 수락) 하거나, 사설 IP 대역이 겹치는 등의 이유로 적절하지 않음
- 엔드포인트 서비스는 서비스를 제공하는 벤더 VPC 에 NLB 혹은 GLB 를 생성하여 이것을 엔드포인트 서비스로 만들어 활용
- 고객 VPC 에서는 인터페이스 엔드포인트를 생성하여 대상 엔드포인트 서비스로 연결. Customer VPC 가 여럿이어도 각각 인터페이스 엔드포인트만 생성하면 됨
[실전] 동일 리전의 S3 버킷에서 대량의 데이터를 읽고 쓰는 서비스가 VPC 의 프라이빗 서브넷 내 EC2 인스턴스에 배포됩니다. 이 서비스는 퍼블릭 서브넷의 NAT 게이트웨이를 통해 S3 와 통신하지만 회사는 데이터 출력 비용을 줄이는 솔루션을 원할 때,
- 해결: NAT 게이트웨이를 통하면 인터넷망으로 연결한다는 의미이므로, VPC 게이트웨이 엔드포인트를 프로비저닝하여 이것을 모든 S3 트래픽의 경로로 사용하도록 프라이빗 서브넷에 대한 라우팅 테이블을 구성
(6) VPN 이란 인터넷을 이용해 가상 사설망(Virtual Private Network)을 구성하는 것으로, VPN 내 디바이스들은 물리적으로 서로 다른 인프라에 있다 할지라도 인터넷에서 IPsec 프로토콜로 구축된 통로(Tunnel)를 통해 같은 사설 네트워크인 것처럼 통신합니다.
AWS 에서는 VPC 의 Site-to-Site VPN 혹은 Client VPN 구성을 통해 VPN 서비스를 제공합니다.
- Client VPN: AWS VPC 에 Client VPN Endpoint 를 구성하고, 랩탑 등 클라이언트 PC 에서
OpenVPN 기반 애플리케이션을 설치하여 VPN Endpoint 와 연결
- Active Directory 등의 자격증명을 이용해 클라이언트가 VPN 을 사용하는 권한을 부여
- 연결은 TLS(전송 계층 암호화) 프로토콜을 통해 구성됨
- Site-to-Site VPN(AWS Managed VPN): IPsec 암호화 프로토콜을 사용하여 VPC 와 온프레미스 간 프라이빗 네트워크 구성
- VPG(Virtual Private Gateway): VPC 내부 리소스들와 VPN 연결할 수 있는 게이트웨이. VPC 콘솔을 통해 구성
- CGW(Customer Gateway): 고객 게이트웨이는 온프레미스의 라우터(Customer Router) IP 등 고객단 정보를 토대로 생성. VPC 콘솔을 통해 구성되지만, 논리적으로 온프레미스에 있는 고객 게이트웨이로써 역할 수행
- VPG 와 CGW 간의 IPsec 터널을 인터넷망에서 구성하는 방식
- 온프레미스 네트워크 관리자는 VPC 와의 VPN 연결을 위해 고객 게이트웨이 환경, 즉 온프레미스에 물리적 또는 소프트웨어 어플라이언스 환경을 구성해야 함(고객 게이트웨이 디바이스 구성)
- S2S VPN 터널당 최대 대역폭은 1.25Gbps 이며, AWS Direct Connect 의 백업으로 사용 가능
- VPG 대신 Transit Gateway 를 S2S VPN 연결 게이트웨이로 사용 가능
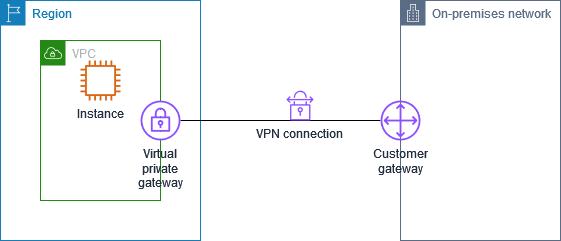
[실전] 회사는 AWS 리전을 온프레미스 인프라의 재해 복구 위치로 사용하고자 하고, 온프레미스에는 기존 10TB 의 데이터와 1Gbps 인터넷 연결이 있습니다. 솔루션 설계자는 회사가 암호화되지 않은 채널을 사용하여 전송하지 않고, 72시간 내에 AWS 에서 기존 데이터를 가질 수 있는 솔루션을 찾아야 합니다.
- 해결: VPC 와 회사 데이터 센터 간 VPN 연결 설정. S2S VPN 은 IPsec 암호화 프로토콜을 사용하므로 조건을 만족함
- (X) Direct Connect 구성은 전용선을 연결할 뿐, 별도의 전송 중 암호화 조치가 없기 때문에 부적절. 만약 사용하고자 한다면 전용선에 VPN 을 추가로 구축해야 함
- (X) Snowball 엣지 등은 배송시간이 있기 때문에 72시간 요건에 맞지 않음(보통 1주일 소요)
(7) Direct Connect 는 AWS 와 온프레미스 간에 DX(Direct Connect) 로케이션을 통한 전용선을 구축하여 프라이빗 네트워크 연결을 생성하는 서비스입니다. 이 때는 인터넷망을 이용하지 않고 전용선을 이용합니다. 우리나라의 경우 DX 로케이션으로 KT, SK 등의 통신사 데이터센터를 이용합니다.
- VPC 에서 VIF(Virtual Interface) 를 생성하여 DX 로케이션의 라우터와 백본 연결, 온프레미스에서도 DX 로케이션과 전용선 연결하여 VPC <-> DX Location <-> On-Premise 간 전체 라인 구축
- 인터넷 비용이 따로 들지 않으며 S2S VPN 보다 안정적이고, 물리적 구성이 필요하므로 설치 시간이 오래 걸림
- 일반적인 VPN 과 같은 방식의 암호화를 지원하지 않기 때문에(ex. IPsec), Direct Connect 에서 전송 중 암호화를 만족시키려면 전용선 내 추가적인 VPN 연결을 구성해야 함
- 포트 당 1Gbps, 10Gbps, 100Gbps 연결 속도 사용 가능
(8) 피어링은 1:1만 가능하고 전이적인 연결이 불가능하지만, Transit Gateway 를 구성하면 이런 문제를 해결할 수 있습니다.
특히, 많은 수의 VPC 각각에서 온프레미스 데이터센터로 VPN, Direct Connect 연결을 구성해야 하는 경우, 모든 VPC 마다 개별적인 VPG 를 사용하기보다 하나의 Transit Gateway 를 사용하는 것이 바람직합니다.
(9) AWS 인프라 구축 시 데이터 전송 비용(Data Transfer Charge)은, 동일 가용 영역 내(0 $/GB) <
동일 리전의 서로 다른 가용 영역(0.02 $/GB, IN/OUT 각각 0.01씩) <
서로 다른 리전 간(0.04 $/GB, IN/OUT 각각 0.02씩) 순서로 비싸집니다.
그 외에는 기본적으로 AWS 내부 서비스에서 외부(인터넷)으로 나가는 비용은 존재하고, 안으로 들어오는 비용은 무료입니다.
다음의 상세 다이어그램을 참조하세요.
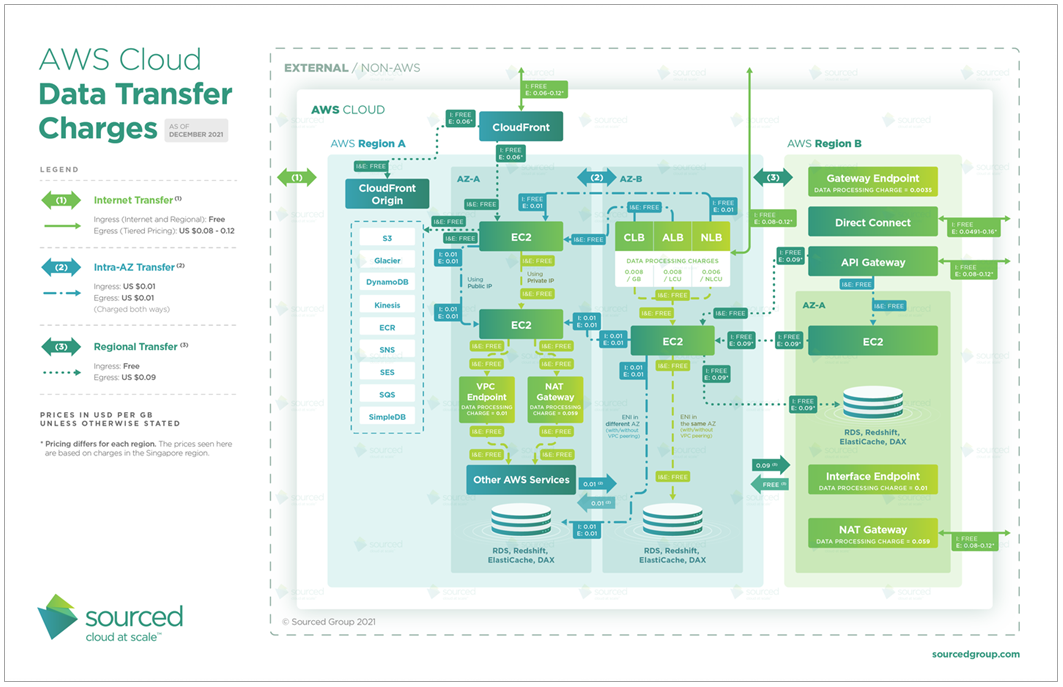
[실전] 솔루션 설계자가 대용량 데이터의 일괄 처리를 처리할 애플리케이션을 만들고 있을 때, 데이터는 여러 EC2 인스턴스 간 네트워크를 통해 전송된다고 합니다. 전송 비용을 줄이기 위해서는,
- 해결: 모든 인스턴스를 동일한 가용 영역에 배치. 동일 가용 영역이면 네트워크 전송 비용이 들지 않음
- (X) 동일 리전이어도 서로 다른 가용 영역이면 전송 비용이 발생함
인프라 자동화
(1) CloudFormation 은 코드를 통해 인프라를 프로비저닝, 관리하는 서비스입니다.(Infrastructure as Code) 쉽게 말해 같은 인프라를 여러 리전에 자동으로 구축할 수 있습니다.
- 구성 요소: Template(Json 또는 YAML 형식의 파일), Stack(Template 을 사용해 생성된 리소스), Change Set(Stack 리소스 변경 사항에 대한 세트)
빌드 방식은 Template 파일을 업로드하여 스택을 생성합니다. AWS 에서 제공하는 WordPress 템플릿을 이용해 실습을 권장합니다.
컴퓨팅 관련
(1) 컨테이너 서비스: OS 위에 컨테이너 엔진을 기동하여 여기에서 특정 애플리케이션 구성 라이브러리 패키지를 실행하게 됩니다. 컨테이너 엔진 위에서 기존에 구성한 컨테이너 이미지를 실행할 수만 있다면 OS 로부터 독립적이기 때문에 어떤 플랫폼에서도 그대로 구현이 가능합니다. 컨테이너는 주로 마이크로서비스에서 사용되며, 대표적인 컨테이너 서비스로는 Kubernetes 와 Docker 가 있습니다.
AWS 에서 컨테이너 서비스는 다음과 같습니다.
- ECS(Elastic Container Service): Docker 컨테이너를 배포 및 관리하는 오케스트레이션 서비스. 오케스트레이션이란, 여러
컨테이너를 중앙에서 동시에 관리하는 의미
- ECS 클러스터 생성: 인프라는 용량 공급자 2개로 기본 Fargate(서버리스) 로 구성되며, 여기에 EC2 인스턴스 ASG 혹은 ECS Anywhere 외부 인스턴스(온프레미스 연결) 추가가 가능
- 태스크 정의: 배포하고자 하는 Docker 이미지 URI 를 활용하여 적절한 서버 용량 지정 후 태스크 생성 (ex. nginx 이미지) 이 때는 해당 서비스의 트래픽을 허용하는 보안그룹(SG)을 별도로 생성
- 서비스 생성: 생성한 ECS 클러스터의 서비스 탭에서 앞서 정의한 태스크를 기반으로 보안 그룹을 적용하여 서비스 배포. 태스크 개수를 조정하여 클러스터 내에서 몇 개의 컨테이너를 운용할 지 설정 가능, 선택 사항으로 앞단에 로드밸런싱도 설정 가능함
- EKS(Elastic Kubernetes Service: AWS 에서 Kubernetes 를 실행하는 서비스. Kubernetes 란 대규모 컨테이너 애플리케이션을 배포 및 관리하는 오픈소스 컨테이너 오케스트레이션 시스템
- AWS Fargate: 서버리스 컨테이너 서비스로 ECS 및 EKS 와 연동되어 컨테이너를 자동으로 관리. 자동으로 관리하기 때문에 사용자는 서버 프로비저닝, 패치 적용, 클러스터 용량 관리 또는 인프라 관리를 따로 할 필요가 없음
- ECR(Elastic Container Registry): Docker 등의 컨테이너 이미지를 공유 및 배포하는 관리 서비스
[실전] Docker 컨테이너로 구축된 애플리케이션을 호스팅하되, 수요에 따라 적절하게 확장 및 축소되어야 하며 추가 운영 오버헤드나 인프라를 초래하지 않기 위해서는 다음의 솔루션을 구성합니다.
- (O) AWS Fargate 와 함께 ECS 혹은 EKS 를 사용
(2) 대표적인 아마존의 Serverless 서비스는 AWS Lambda, AWS Fargate, S3, DynamoDB, Aurora Serverless, SNS, SQS, API Gateway 가 있습니다. 실제로 서버가 없는 것은 아니고 서버 용량조정, 프로비저닝, 패치 등의 인프라 관리를 AWS 에서 담당하므로 사용자가 따로 관리할 필요가 없기 때문에 서버리스로 불립니다.
- Lambda: 코드를 실행하여 동작하는 서버리스 컴퓨팅으로 이벤트 위주로 트리거되며
다른 AWS 서비스(S3, DynamoDB, SNS, SQS 등)와 결합하여 사용됨. 요청할 때만 시스템을 사용하는 온디맨드 방식의 이벤트 중심의 실행
(함수가 최대 15분 이상 돌 수 없으며 한 번에 1000건 이상 실행 불가)
- ex. S3 이미지 파일 업로드 시 파일 사이즈 조정하는 함수
- hello-world-python 함수 예제 진행하기
[실전] 스타트업 회사의 프로토타입 마이크로서비스 애플리케이션에서 빠르게 수정 및 배포에 용이한 Serverless 를 많이 이용합니다. 특히 Lambda 는 이벤트 발생 시에만 코드가 실행되므로, 순간적인 오버헤드에 자동 대응이 가능하며 비용효율적입니다. 하지만 서버가 벤더사인 AWS 에 종속되며 별도의 저장공간(하드디스크)이 존재하지 않는다는 단점이 있습니다.
(3) Elastic Beanstalk 는 웹 애플리케이션을 배포하고 운영하는 서비스로, 인프라 리소스를 직접 구성하지 않고 애플리케이션 코드에만 집중할 수 있도록 합니다. 따라서 코드를 업로드하기만 하면 용량 프로비저닝, 로드밸런싱, Auto Scaling 부터 상태 모니터링 등의 배포를 AWS 가 자동으로 처리합니다. 이러한 서비스를 PaaS(Platform-as-a-Service) 라고 합니다.
- 대부분의 언어 플랫폼 지원: Java, .NET, PHP, Node.js, Python, Ruby, Go / Docker 웹 애플리케이션 지원
- 지정한 언어 플랫폼에 해당하는 애플리케이션 코드를 업로드하고 생성하면 됨
- 워크플로: Create Application > Upload Version > Launch Environment > Manage Environment
[실전] Elastic Beanstalk 는 EC2 자원관리, 로드 밸런싱, 오토 스케일링 등의 인프라적 요소를 자동으로 배포 및 관리하는 서비스로 개발자로 하여금 소스코드에만 집중할 수 있도록 합니다. AWS 에 의해 인프라가 자동 관리된다는 사실은 기술적 요구도가 적으며 할인된 가격으로 인프라 비용이 청구된다는 것을 의미하기도 합니다. 이러한 점은 반대로 SG 설정불가, VPC 구성 변경 불가 등 인프라를 사용자가 원하는 대로 커스터마이징 할 수 없다는 단점으로 이어집니다.
(4) 다음의 머신러닝 서비스들의 개념을 이해하도록 합시다.
- Comprehend: 텍스트 안에서 특정 항목을 찾아내는 서비스 (ex. 회사 이름, 부정적인 후기 등)
- Rekognition: 이미지, 비디오 분석 (얼굴 탐지, 사물 인식)
- Polly: 텍스트를 음성으로 변환하는 서비스
- Lex: 음성인식 서비스, 챗봇 구현 가능
- Textract: 스캔문서에서 문자, 테이블, 양식 추출 섭시ㅡ
- Translate: 번역 서비스
- Transcribe: 음성을 텍스트로 변환
- SageMaker: 머신러닝 모델을 구축, 훈련 및 배포하는 서비스
- Forecast: 머신러닝 기반 비즈니스 지표 분석 및 시계열 예측 서비스
- Kendera: 지능형 검색 서비스, 간단한 키워드 외에도 자연어 질문을 사용해 원하는 답을 얻을 수 있음 (텍스트 조각, FAQ, PDF 등 관계없음)
- Personalize: Amazon.com 에서 실시간 맞춤화 추천에 사용하는 것과 동일한 ML 기술로 애플리케이션 구축이 가능한 서비스 특정 제품 추천, 맞춤화된 제품 순위 재지정, 맞춤화된 직접 마케팅 등 맞춤화 환경 애플리케이션을 손쉽게 구축 가능
- Amazon Connect: 클라우드 기반 고객센터 서비스. (전화, 자동 음성응답, 챗봇 등 기술 통합 기능)
재해 복구
(1) Disaster(재해)란 비즈니스에 심각한 부정적인 영향을 주는 사건을 말합니다.
- Natural disasters(지진, 홍수), Technical failures(정전, 네트워크 장애), Human actions(부주의한 조작/설정, 액세스 제한 실패)
이러한 재해를 극복하는 방법으로 High Availability 와 Disaster Recovery 가 있는데, 이 둘은 엄밀히 다른 개념이라는 점을 인지해야 합니다.
(2) Disaster Recovery(재해 복구) 는 비즈니스의 연속성을 목표로 전체 워크로드를 별도의 장소에 복사하여 지진, 홍수 등의 재난 이벤트에 대응할 수 있도록 합니다.
재해 복구는 특정 서비스를 지속하기 위해 일부 워크로드(워크로드 구성요소)를 다른 가용 영역에 복사하는 고 가용성과는 차이가 있습니다. 고 가용성의 목표는 시스템의 기능 수행 시간의 최대화에 있습니다.
- 재해 복구의 목표
- Recovery Point Objective(RPO, 복구 시점 목표): 얼마만큼의 데이터 손실을 감수할 수 있는가? 백업 기간과 유형에 따라 다름
- Recovery Time Objective(RTO, 복구 시간 목표): 재해 발생 후 복구 목표 시간. 비즈니스 다운 타임 허용시간. 장애 조치 시스템 설계에 따라 다름

- 재해 복구 전략
- (active/passive) Backup & Restore: Hours, 데이터 백업 및 장애발생 시 백업으로부터 복구
- (active/passive) Pilot Light: 10s of minutes, 코어 시스템만 복제 후 대기 (ex. RDS replica set)
- (active/passive) Warm standby: Minutes, 전체 시스템을 더 작은 스케일로 구성하여 대기
- (active/active) Multi-site active/active: Real-time, 전체 시스템을 동일하게 복제하여 동시 운영. 가장 비싸므로 Mission critical 한 서비스에서 사용

[실전] DynamoDB 를 사용하는 앱에서 데이터 손상 발생 시 RPO 15분 및 RTO 1시간을 충족하는 솔루션을 설계하는 경우,
- 해결: DynamoDB 의 지정 시간 복구(point-in-time recovery)를 구성하고, 원하는 RPO 시점으로 복원. 지정 시간 복구는 최소 5분부터 최대 35일 중 선택
- (X) DynamoDB 의 글로벌 테이블 구성은 여러 리전에 복제본을 생성하는 것이므로, 손상된 데이터까지 복제되어 부적절
- (X) 백업 시스템이 매일 S3 Glacier 로 내보내게 구성되었다면, RPO 24H 이므로 부적절
- (X) 백업을 위해 EBS 스냅샷을 사용한다면, 스냅샷 비용적인 문제와 RTO 는 수 시간 소요로 부적절
[실전] ASG 의 ELB 뒤에서 DynamoDB 테이블로 구성된 애플리케이션 호스팅이 존재할 때, 다운타임을 최소화하면서 다른 AWS 리전에서 애플리케이션을 사용할 수 있도록 하는 솔루션은,
- 해결: 재해 복구 지역에 ASG 과 로드밸런서 생성, DynamoDB 는 전역 테이블로 구성, 새 재해 복구 지역의 로드밸런서를 가리키도록 DNS 장애 조치를 구성
- (X) CloudFormation 은 ASG 의 대안이 될 수 없으며, 다운타임이 발생할 수 있음
- (X) 재해 복구 로드밸런서를 가리키는 R53 을 업데이트하는 Lambda 함수를 트리거하는 CloudWatch 경보를 생성하는 것보다 그냥 R53 의 장애 조치 라우팅을 사용하는 것이 더 적절한 솔루션
Written on February 24th, 2023 by namu[실전] 단일 리전의 EC2 인스턴스에서 애플리케이션이 실행 중일 때, 재해 발생 시 리소스를 두 번째 리전에도 배포할 수 있도록 하려면,
- 해결: (1) EC2 인스턴스의 AMI 를 복사하고 대상에 대해 다른 리전을 지정한 후 (2) 새 리전의 AMI 에서 (복사된 AMI 를 대상으로) 새 EC2 인스턴스를 시작
- (X) 인스턴스의 볼륨을 S3 에 복사하여 이것을 새 리전의 새 인스턴스에 복사하는 방식은 비효율적